Oracle interview questions evaluate your technical skills and knowledge in addition to soft skills such as problem-solving, leadership, communication, and teamwork. The depth of the Oracle questions asked in interviews depends on your experience and the level and role at which you are hired.
Oracle looks for software engineers with core technical skills, system focus, quality and maintenance, specialized and niche skills in AI and ML, technical depth and coding, and behavior aligned with Oracle’s culture.
The technical Oracle interview questions and answers (2026) guide presents questions and answers for freshers, intermediate, and experienced developers on several key topics asked in Oracle interviews. The guide covers the interview process, Oracle database, coding, system design, and behavioral.
Oracle looks for a mix of hard and soft skills in software engineers. Oracle interview questions evaluate the technical depth and width, problem-solving and analytical ability, and the professional mindset. Senior-level candidates must have experience with massive implementations and leadership skills.
The following table presents the skills that Oracle evaluates and why they matter:
| Skill Area | What Oracle Looks For | Why It Matters |
|---|---|---|
| Problem Solving | Ability to break down complex problems, apply DSA, optimize solutions | Critical for efficient code for large enterprise systems; affects performance and scalability |
| SQL Knowledge | Expert command of queries, joins, indexing, normalization, query optimization | Oracle product is databases; efficient queries enhance application performance |
| Database Architecture | Understanding of schema design, transactions, ACID properties, scalability | Helps in designing reliable systems using Oracle Database and handling large data efficiently. |
| System Design Thinking | Ability to design scalable, distributed systems, APIs, microservices | Important for building enterprise-grade applications and cloud services like Oracle Cloud Infrastructure. |
| Communication & Teamwork | Clear articulation of ideas, collaboration, and explaining trade-offs | Oracle teams are globally distributed. Clear communication is needed for smooth development. |

The Oracle interview process is spread over four main stages with multiple rounds in each. The depth of questions depends on the role and experience of the candidate. Junior levels see more tech-heavy coding, while questions for senior levels are on vision and adding value.
The following table shows what Oracle tests in the interviews.
| Interview Stage | What Oracle Tests |
|---|---|
| Recruiter screen | Check qualification, experience, and if they are aligned with Oracle requirements. Check basic etiquette. If claims are genuine, and alignment |
| Online Aptitude and Coding Test | AI environment and IDE. Check expertise with technologies and coding |
| Technical Interview Rounds | Evaluate coding skills, logical and analytical capability, speed and adaptation, and behavior |
| HR / Behavioral Round | Evaluate behavior, leadership, positive attitude, personality, and fitness to work with multiple teams |
Also Read: 60+ Java Interview Questions and Answers You Must Know (Updated 2026)
This section presents basic Oracle interview questions that will help freshers to prepare for advanced Oracle questions asked in interviews. In this guide, the questions have been divided into basic, intermediate, and advanced.
Q1. What is Oracle Database?
Oracle database is a relational database management system from Oracle Corporation to store, manage, and retrieve structured data efficiently with SQL. Organizations organize massive data securely and access specific information and transactions as needed.
Q2. What is SQL?
Structured Query Language (SQL) is used to query, update, and delete in databases such as the Oracle database.
Q3. What is the difference between SQL and PL/SQL?
SQL is used to query and manipulate databases. Procedural Language/SQL (PL/SQL) is used to write programs with logic by executing a code block.
The following table compares SQL and PL/SQL.
| Feature | SQL (Structured Query Language) | PL/SQL (Procedural Language/SQL) |
|---|---|---|
| Type | Declarative language | Procedural language |
| Purpose | Data querying and manipulation | Writing complete programs with logic |
| Execution | Executes one statement at a time | Executes a block of statements |
| Focus | What to do | How to do |
| Developer | Standard language | Developed by Oracle Corporation |
| Variables | Not supported | Supported |
| Control Flow | No loops or conditions | Supports IF, LOOP, WHILE |
| Error Handling | Limited | Supports exception handling |
| Code Structure | Simple queries | Structured blocks (BEGIN–END) |
| Performance | Slower for multiple operations | Faster (reduces multiple calls) |
| Usage | SELECT, INSERT, UPDATE, DELETE | Procedures, Functions, Triggers |
| Integration | Used alone | Works with SQL inside programs |
Q4. What is a Primary Key in Oracle?
A primary key in Oracle is a type of constraint applied to columns that uniquely identifies each row in a table, ensuring data integrity. It does not allow NULL values or duplicate data. A table has only one primary key, and Oracle automatically assigns a unique index to enforce it.
Q5. What are Indexes in Oracle?
An index is a database object that improves the data retrieval speed from a table. As in a large book, instead of referencing each page and headline, the index directly points to a page. The following table briefly describes different indexes and their use case.
| Index Type | Description | Best Use Case and when to use |
|---|---|---|
| B-Tree Index | Default index type; stores data in a balanced tree structure | High-cardinality columns (many unique values). Frequently used in WHERE, JOIN, ORDER BY |
| Bitmap Index | Uses bitmaps (0s and 1s) to represent data | Low-cardinality columns with few distinct values, like gender, status, data warehouse / read-heavy systems |
| Function-Based Index | Index created on the result of a function or expression | When queries use functions (UPPER, LOWER, TRUNC, etc.) Example: WHERE UPPER(name) = ‘JOHN’ |
| Unique Index | Ensures all indexed values are unique | Enforcing uniqueness, such as email and username. Automatically created for PRIMARY KEY / UNIQUE constraint. |
| Composite Index | Index on multiple columns | When queries filter on multiple columns together, Example: department_id, salary |
Q6. What is the difference between a Table and a View?
The main difference between a table and a view is that a table is a physical storage structure with data. A view is a virtual representation of data obtained from multiple tables.
The following table gives the difference between a table and a view.
| Feature | Table | View |
|---|---|---|
| Definition | Physical object storing actual data | Virtual object based on a query |
| Storage | Stores data on disk | Does not store data (stores query only) |
| Data | Contains real rows and columns | Displays data from one or more tables |
| Performance | Faster for direct data access | Depends on underlying query |
| Complexity | Simple structure | Can combine multiple tables (JOINs) |
| Update | Fully updatable (INSERT, UPDATE, DELETE) | Limited updates (depends on view type) |
| Security | Less flexible | Can restrict access to specific columns |
| Use Case | Store and manage data | Simplify complex queries / restrict data |
| Dependency | Independent | Depends on base tables |
| Index Support | Supports indexes | Cannot have indexes (except materialized views) |
Q7. What is the purpose of the COMMIT statement?
The COMMIT statement permanently saves all changes in the current transaction. All operations and actions of INSERT, UPDATE, and DELETE are saved, changes are available for users, current transactions end, and rollback of the changes is prevented.
Code snippet of COMMIT statement is:
-- Start transaction (implicit)
INSERT INTO employees (emp_id, name)
VALUES (101, 'John');
UPDATE employees
SET name = 'John Doe'
WHERE emp_id = 101;
-- Save changes permanently
COMMIT;
Q8. What is the purpose of the ROLLBACK statement?
The ROLLBACK statement undoes changes made in the current transaction. It reverts INSERT, UPDATE, and DELETE operations done after the last COMMIT, and restores data to the previous state. Current transactions end, and data integrity is maintained.
Code snippet for the ROLLBACK statement is:
-- Insert a record
INSERT INTO employees (emp_id, name)
VALUES (101, 'John');
-- Update the record
UPDATE employees
SET name = 'John Doe'
WHERE emp_id = 101;
-- Undo all changes
ROLLBACK;
Q9. What is the difference between CHAR and VARCHAR2?
CHAR gives a fixed size of pad spaces. If it is used often, it forms hidden trailing spaces that must be trimmed by applications before they can “find” the data again.
VARCHAR2 allows for variable size and efficient storage. It is used for fixed-length data like Gender (M/F). It is used to avoid the unique blank-padding behaviors of CHAR that can cause issues in application-level comparisons.
The following table compares CHAR and VARCHAR2.
| Feature | CHAR | VARCHAR2 |
|---|---|---|
| Type | Fixed-length string | Variable-length string |
| Storage | Always uses full defined length | Uses only actual data length |
| Padding | Padded with spaces if data is shorter | No padding |
| Performance | Slightly faster for fixed-size data | More efficient for variable data |
| Space Usage | Wastes space if data is small | Saves space |
| Max Size | Up to 2000 bytes | Up to 4000 bytes |
| Use Case | Fixed values (e.g., country code, gender) | Variable values (e.g., name, email) |
| Flexibility | Less flexible | More flexible |
Q10. What is the NVL Function in Oracle?
The NVL function replaces NULL values with a specified default value. It handles missing data, avoids NULL-related problems in calculations, and is used in SELECT statements. A code snippet of the NVL function in Oracle is:
SELECT name, NVL(salary, 0) AS salary
FROM employees;
Important questions and answers for intermediate-level Oracle interviews are presented in this section.
Q11. What is Database Normalization?
Database Normalization organizes data to reduce redundancy and improve data integrity. It divides large tables into smaller, related tables and defines relationships between them. Using forms and rules, it removes duplicate data, updates, deletes, and inserts data to make the database responsive.
The following table explains database normalization rules and forms.
| Normal Form | Rule / Condition |
|---|---|
| 1NF (First Normal Form) | The table should include atomic (indivisible) values. Repeating groups or multi-valued columns are not allowed and all records must be uniquely identifiable (Primary Key) |
| 2NF (Second Normal Form) | It must be in 1NF – No partial dependency a non-key attribute must depend on the whole primary key |
| 3NF (Third Normal Form) | It should be in 2NF – No transitive dependency. Non-key attributes depend only on the primary key, not on other non-key attributes |
| BCNF (Boyce-Codd Normal Form) | It should be in 3NF. Each determinant should be a candidate key |
| 4NF (Fourth Normal Form) | It has to be in BCNF. Multi-valued dependencies are not allowed. |
| 5NF (Fifth Normal Form) | Should be in 4NF. Join dependencies are not allowed and the table cannot be further decomposed without losing data |
Q12. What is the Difference Between UNION and UNION ALL?
The difference between UNION and UNION ALL is in the way they handle duplicate rows to combine results from multiple queries. UNION removes duplicate rows and presents only distinct results. UNION ALL retains all rows along with duplicates.
Comparison table of UNION and UNION ALL is:
| Aspect | UNION | UNION ALL |
|---|---|---|
| Duplicate Handling | Removes duplicates | Keeps duplicates |
| Performance | Slower (due to duplicate checking) | Faster (no duplicate checking) |
| Sorting/Processing | Requires extra processing (DISTINCT) | Minimal processing |
| Result Set | Unique rows only | All rows (including duplicates) |
| Use Case | When you want clean, unique results | When duplicates are acceptable |
Q13. What is the GROUP BY Clause in SQL?
The GROUP BY clause in SQL groups rows with the same values in specified columns to allow aggregate functions on each group. GROUP BY is used with COUNT(), SUM(), AVG(), MAX(), and MIN().
Sample code to count employees as per the department ID is:
SELECT department_id, COUNT(*) AS total_employees
FROM employees
GROUP BY department_id;
Q14. What is a Foreign Key?
A Foreign Key is a set of columns or a column in a table that refers to the Primary Key in another table to form a relationship between the two tables. It links tables, maintains data integrity, and ensures that values exist in the parent table.
Q15. What is a Subquery in Oracle?
A subquery in Oracle is a query inside another SQL query. It is used to retrieve data that will be used by the main (outer) query.
Code example to find employees in New York for a department ID is:
SELECT employee_name
FROM employees
WHERE department_id IN (
SELECT department_id
FROM departments
WHERE location = 'New York'
);
Q16. What is a Sequence in Oracle?
A Sequence is an object in the database that creates unique numeric values automatically, such as primary keys and employee IDs. It generates a number as per the specified order, without duplication, and does not depend on a table.
Values are in increments; they do not decrease automatically, and gaps can happen from caching and rollback.
Code example using Sequence in Oracle to generate the next value is:
SELECT emp_seq.NEXTVAL FROM dual;
Q17. What is a Bitmap Index?
A bitmap index is an index that uses bitmaps or binary vectors of 0s and 1s to represent values in a column, rather than storing actual row pointers like a B-tree index. It is used for fast filtering in columns with low distinct values or low cardinality.
Q18. What is the Difference Between a Stored Procedure and a Function?
A stored procedure is used to run operations such as Insert/Update/Delete. A Function is used to calculate a value in SQL. In other words, a procedure performs an action while a function returns a value.
The following table compares stored procedures and functions.
| Aspect | Stored Procedure | Function |
|---|---|---|
| Return Value | Does not return a value (directly) | Must return a value |
| Return Type | Can return via OUT parameters | Returns a single value using RETURN |
| Usage in SQL | Cannot be used in SELECT statements | Can be used in SELECT, WHERE, etc. |
| Purpose | Perform actions (DML, business logic) | Compute and return a value |
| Parameters | IN, OUT, IN OUT | Mostly IN (OUT not commonly used in SQL) |
| Calling Method | Called using EXEC or PL/SQL block | Called like a normal function |
| DML Operations | Can perform INSERT/UPDATE/DELETE | Restricted when used in SQL |
| Mandatory RETURN | Not required | Required |
| Transaction Control | Can use COMMIT/ROLLBACK | Not allowed (when called in SQL) |
Q19. What is a Trigger in Oracle?
A Trigger is a stored PL/SQL block that automatically fires or runs when a specific event happens in a table or view. It is used to enforce rules automatically, maintain data integrity, and audit changes.
Sample code with Trigger after salary is updated:
CREATE OR REPLACE TRIGGER after_salary_update
AFTER UPDATE OF salary ON employees
FOR EACH ROW
BEGIN
DBMS_OUTPUT.PUT_LINE('Salary updated');
END;
Q20. What is the WITH Clause (Common Table Expression)?
The WITH Clause or Common Table Expression – CTE defines a temporary named result set to reference in a query. It serves as a temporary table and is formed only during query execution. It enhances reusability and readability.
Sample code using the WITH Clause to filter departments with a high average salary.
WITH dept_avg AS (
SELECT department_id, AVG(salary) AS avg_salary
FROM employees
GROUP BY department_id
)
SELECT department_id, avg_salary
FROM dept_avg
WHERE avg_salary > 60000;
This section presents advanced Oracle questions and answers. Senior developers will find this section useful to answer Oracle interview questions.
Q21. What are ACID properties in Oracle Transactions?
Atomicity, consistency, isolation, and durability (ACID) properties are basic rules for reliable and consistent transaction processing even in failure. These are applied for bank transfer, and are the main support for transaction management.
Atomicity considers a transaction as a single unit, and all operations must be applied, or none are. Atomicity stops a step when it fails and runs a ROLLBACK. Consistency ensures a valid state transition to move the database from one valid state to the next. All rules, triggers, constraints, and relationships are forced.
Isolation ensures that transactions run concurrently, independently, and do not interfere with others. This feature stops problems of phantom, non-repeatable, and dirty reads. Durability ensures changes are permanently saved. If the system fails, redo logs recover the data.
The following table lists ACID properties and What It Guarantees in Oracle:
| ACID Property | What It Guarantees in Oracle |
|---|---|
| Atomicity | Ensures that a transaction is all-or-nothing. When part of a transaction fails, Oracle automatically rolls back the transaction with undo data. |
| Consistency | The Guarantees database will always remain in a valid state by enforcing constraints, rules, triggers, and relationships before and after a transaction. |
| Isolation | Ensures that concurrent transactions do not interfere with each other. Oracle provides isolation levels (like Read Committed) to prevent issues such as dirty reads. |
| Durability | Ensures that once a transaction is committed, it is permanently saved, even in case of system failure, using redo logs and recovery mechanisms. |
Q22. What is an Execution Plan in Oracle?
An execution plan gives a detailed roadmap for executing an SQL query. Detailed operation steps used by the optimizer to retrieve or modify data efficiently are given. Components are steps like TABLE ACCESS, INDEX SCAN, and JOIN.
The access path of data retrieval, like full and index scan, is given in the execution plan. Also given are the expected rows and data volume to process. The execution plan is generated by the cost-based optimizer.
Execution plans optimize query performance, bottlenecks are identified with full table scan, which helps index creation, tune performance, and understand the optimizer decisions.
Sample code for execution plan to see the estimated execution plan for the query is given below:
EXPLAIN PLAN FOR
SELECT employee_id, first_name
FROM employees
WHERE department_id = 10;
SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY());
Q23. What are Materialized Views in Oracle?
Materialized views are database objects that store the results of a query physically. They prevent repeated execution of complex queries to improve performance. It has precomputed data in several tables stored physically and is refreshed when base tables are updated.
The following table compares aspects of views and materialized views.
| Aspect | View | Materialized View |
|---|---|---|
| Definition | Virtual table based on a query | Physical copy of query result |
| Storage | Does not store data but only a link | Stores data on disk |
| Data Retrieval | Query runs each time | Precomputed data is returned |
| Performance | Slow while running complex queries | Faster since it is optimized for reads |
| Data Freshness | Always up-to-date | May become stale and needs to be refreshed |
| Refresh Needed | No | Yes, manual or automatic |
| Use Case | Simple queries, abstraction | Reporting, analytics, caching |
| Complex Queries | Less efficient | Highly efficient |
| Index Support | Cannot have indexes directly | Can have indexes |
| Maintenance | Low | Requires refresh management |
Q24. What is the difference between Full Backup and Incremental Backup?
Full backup takes a full and complete copy of the database at a specific point in time. Incremental backup saves only the changed data since the previous backup.
It ensures each file is backed up, and these include datafiles and archived logs, with no dependency on previous backups. It is self-contained, provides fast and easy recovery, but requires more time and storage.
Incremental backup types are of Level 0 and equivalent to a full backup, Level 1 incremental is differential, and changes since the last Level 0 are considered. It is faster, the backup size is small, but it needs a previous backup for recovery.
The table comparing full and incremental backups is given below.
| Aspect | Full Backup | Incremental Backup |
|---|---|---|
| Definition | Complete copy of entire database | Only changed data since last backup |
| Backup Size | Very large | Small |
| Backup Time | Slow | Fast |
| Restore Process | Simple (single step) | Multi-step (chain of backups) |
| Restore Time | Faster | Slower |
| Storage Usage | High | Low |
| Dependency | Independent | Depends on previous backups |
| Failure Risk | Low | Higher (if one backup missing, recovery fails) |
| Network Load | High | Low |
| Use Case | Small DBs, initial backup | Large DBs, frequent changes |
| Maintenance | Easy | Complex |
Q25. How Can You Improve Query Performance in Oracle?
Improving query performance is done with the optimizer, selecting efficient execution paths, and reducing unnecessary load for I/O, CPU, and memory. Some methods to improve query performance are:
A table comparing the strategy to improve query performance and how it helps is given below.
| Strategy | How it helps | When to Use |
|---|---|---|
| Indexing | Faster data retrieval | Frequent filtering/join columns |
| Avoid SELECT * | Reduces data load | Large tables |
| Bind Variables | Reduces parsing overhead | Repeated queries |
| Execution Plan Analysis | Identifies bottlenecks | Performance tuning |
| Updated Statistics | Better optimizer decisions | Regular maintenance |
| Optimized Joins | Efficient data combination | Multi-table queries |
| Materialized Views | Faster complex queries | Reporting/analytics |
| Function-Based Index | Enables index usage with functions | Case-insensitive search |
| Pagination | Limits data returned | UI queries |
| Partitioning | Faster large table access | Huge datasets |
Q26. What is Oracle Data Pump?
Oracle Data Pump is a high-speed data movement utility to export and import data and metadata between databases. It has two tools: EXPDP (Export Data Pump), which exports data, and IMPDP (Import Data Pump), which imports data.
Oracle Data Pump uses dump files and moves tables, schemas, the full database, and metadata with indexes and constraints. Important features are parallel processing, giving high performance, and selected import and export. It runs in network mode, dump files are not needed in network mode, and it gives compression support.
Also Read: Top Database Questions to Ace Your Technical Interview
Oracle interview questions often decide if you crack the interview and land a job. This section presents coding questions asked in Oracle interviews and answers with code samples.
Q27. Implement a Queue Using Two Stacks
A queue is used for communication with asynchronous messaging for different applications and system components by sending and receiving messages without being directly connected. A queue uses FIFO (First In, First Out), and a stack follows LIFO (Last In, First Out) order.
FIFO Queue works in multiple steps, and these are: Enqueue, where an element is added, and Dequeue, where the element is removed. Time complexity O(1) is through the enqueue operation, and dequeue is with the O(1) amortized operation. Space complexity O(n) stores the elements in two stacks.
The following code is used to implement a queue using FIFO and two stacks (LIFO).
import java.util.Stack;
class QueueUsingStacks {
private Stack<Integer> inStack = new Stack<>();
private Stack<Integer> outStack = new Stack<>();
// Enqueue operation
public void enqueue(int x) {
inStack.push(x);
}
// Dequeue operation
public int dequeue() {
if (outStack.isEmpty()) {
// Transfer elements from inStack to outStack
while (!inStack.isEmpty()) {
outStack.push(inStack.pop());
}
}
if (outStack.isEmpty()) {
throw new RuntimeException("Queue is empty");
}
return outStack.pop();
}
// Peek operation
public int peek() {
if (outStack.isEmpty()) {
while (!inStack.isEmpty()) {
outStack.push(inStack.pop());
}
}
if (outStack.isEmpty()) {
throw new RuntimeException("Queue is empty");
}
return outStack.peek();
}
public boolean isEmpty() {
return inStack.isEmpty() && outStack.isEmpty();
}
}
Q28. Merge Two Sorted Linked Lists
Merging two sorted linked lists is frequently asked in Oracle interview questions. The objective is to combine two singly sorted linked lists, in non-decreasing order, into a single sorted linked list by splicing the existing nodes together.
The process starts by comparing the first nodes of the two lists and selecting the smaller value, and placing it in the result list. The process is repeated until one list is empty, and then the remaining parts are attached to the other list.
Time complexity expression is O(n+m), where n is the length of list 1 and m is the length of list 2. Space complexity expression is O(1), constant space, and extra data structures are not used.
The following code compares nodes and reuses existing nodes to merge two sorted linked lists into one sorted list.
class ListNode {
int val;
ListNode next;
ListNode(int v) { val = v; }
}
public ListNode merge(ListNode l1, ListNode l2) {
if (l1 == null) return l2;
if (l2 == null) return l1;
if (l1.val < l2.val) {
l1.next = merge(l1.next, l2);
return l1;
} else {
l2.next = merge(l1, l2.next);
return l2;
}
}
Q29. Find the Lowest Common Ancestor in a Binary Tree
The Lowest Common Ancestor (LCA) of two nodes, p and q, in a binary tree is the deepest node that has both p and q as descendants. A node can be a descendant of itself with p an ancestor of q, then the LCA is p.
It is used to find the distance between nodes, solve structural problems in tree-based data structures of 1 or 2, hierarchical relationship analysis, network routing, and modelling biological data.
Time complexity is O(n) with a visit to each node once. Space complexity is O(h), the height of the tree due to the recursion stack.
Sample code to find the LCA of two nodes in a binary tree with the lowest nodes where both ends meet.
class TreeNode {
int val;
TreeNode left, right;
TreeNode(int x) { val = x; }
}
public TreeNode lca(TreeNode root, TreeNode p, TreeNode q) {
if (root == null || root == p || root == q) return root;
TreeNode left = lca(root.left, p, q);
TreeNode right = lca(root.right, p, q);
return (left != null && right != null)
? root
: (left != null ? left : right);
}
Q30. Count Inversions in an Array
Inversion count of an array is about finding the number of pairs (i, j) so that i < j and arr[i] > arr[j]. It measures how far an array is from being sorted. It is used to measure data disorder, obtain ranking and preference analysis, for bioinformatics, and algorithm performance analysis.
Time complexity is O(nlog n) with merge divides, and space complexity is O(n) with a temporary array used in merge.
The following sample code counts inversions in an array for pairs (i,j) where i <j and arr[i] > arr[j].
int countInversions(int[] arr) {
return mergeSort(arr, 0, arr.length - 1);
}
int mergeSort(int[] arr, int l, int r) {
if (l >= r) return 0;
int m = (l + r) / 2;
return mergeSort(arr, l, m)
+ mergeSort(arr, m + 1, r)
+ merge(arr, l, m, r);
}
int merge(int[] arr, int l, int m, int r) {
int[] temp = new int[r - l + 1];
int i = l, j = m + 1, k = 0, inv = 0;
while (i <= m && j <= r) {
if (arr[i] <= arr[j]) temp[k++] = arr[i++];
else {
temp[k++] = arr[j++];
inv += (m - i + 1); // key step
}
}
while (i <= m) temp[k++] = arr[i++];
while (j <= r) temp[k++] = arr[j++];
System.arraycopy(temp, 0, arr, l, temp.length);
return inv;
}
Q31. Find the Next Greater Element
The next greater element for an element x in an array is the first element to its right, greater than x. If such an element is not found, the result is -1. It is solved with a monotonic stack for O(n) complexity. It is used in stock plan and price analysis, array optimization, temperature monitoring, histogram problems, and in circular arrays.
Time complexity is O(n) with each element pushed and popped once, and space complexity is O(n) for the stack and result array.
Sample code to find the next greater element to the right for each element in the array is:
import java.util.*;
public class NGE {
public static void main(String[] args) {
int[] arr = {4, 5, 2, 25};
Stack<Integer> stack = new Stack<>();
for (int i = arr.length - 1; i >= 0; i--) {
while (!stack.isEmpty() && stack.peek() <= arr[i]) {
stack.pop();
}
int nge = stack.isEmpty() ? -1 : stack.peek();
System.out.println(arr[i] + " -> " + nge);
stack.push(arr[i]);
}
}
}
Tips to crack Oracle interview questions are given in the following table.
| Tip | Details |
|---|---|
| Practice Coding Problems | Practice is the key. Register on code test platforms and solve problems on arrays, strings, and recursion. Focus on patterns such as sliding windows, two pointers, stack, and go for consistency, accuracy, and speed. |
| Focus on Arrays, Trees, Graphs, DP | These are critical topics asked in Oracle interview questions. Learn traversal DFS/BFS) recursion, and dynamic programming patterns like memoization and tabulation. |
| State Time & Space Complexity | Explain complexity after coding to show problem-solving skills. Example: “Time = O(n), Space = O(n)”. |
| Write Clean, Readable Code | Use meaningful variable names, proper indentation, and modular functions. Interviewers value readability as much as correctness. |
| Test Edge Cases Aloud | Speak of cases like empty array, single element, large input, duplicates. This shows attention to detail and prevents bugs. |
| Think Before Coding | Take 1–2 minutes to clarify the approach before writing code. Avoid jumping straight into coding. |
| Communicate Clearly | Explain your logic steps while coding. |
| Optimize After Brute Force | Start with a simple solution, then improve it. Shows problem-solving progression. |
| Use Examples to Explain | Walk through a small example to validate your approach before coding. |
| Stay Calm & Structured | Even if stuck, explain your thought process. Interviewers care about how you think, not just the final answer. |
Also Read: 40+ SQL Interview Questions and Answers to Crack Your Next Interview (2026)
Oracle system design interview questions evaluate your grasp of theory, and designing real-world systems.
Q32. Design a Parking Management System
The component diagram of the parking management system design is given below.
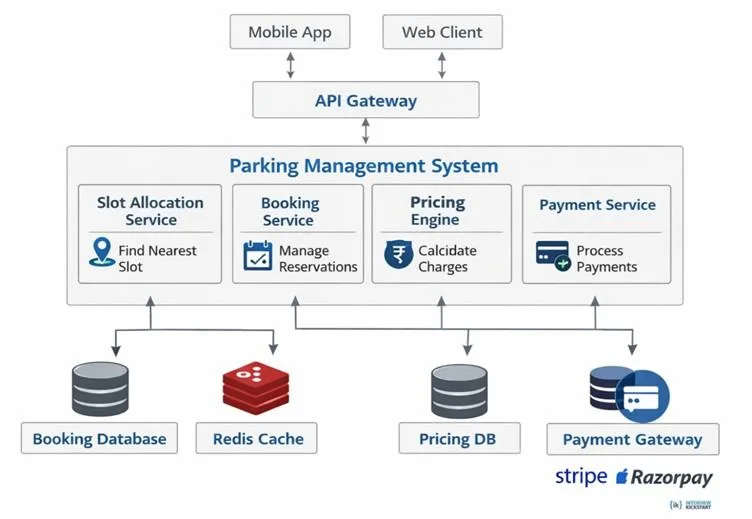
Key components of the parking management system design are:
Q33. Design an Online Bookstore
Questions to ask the interviewer:
Key components:
Q34. Design a Messaging Service
Clarifying questions to ask the interviewer:
Key components of the messaging service are:
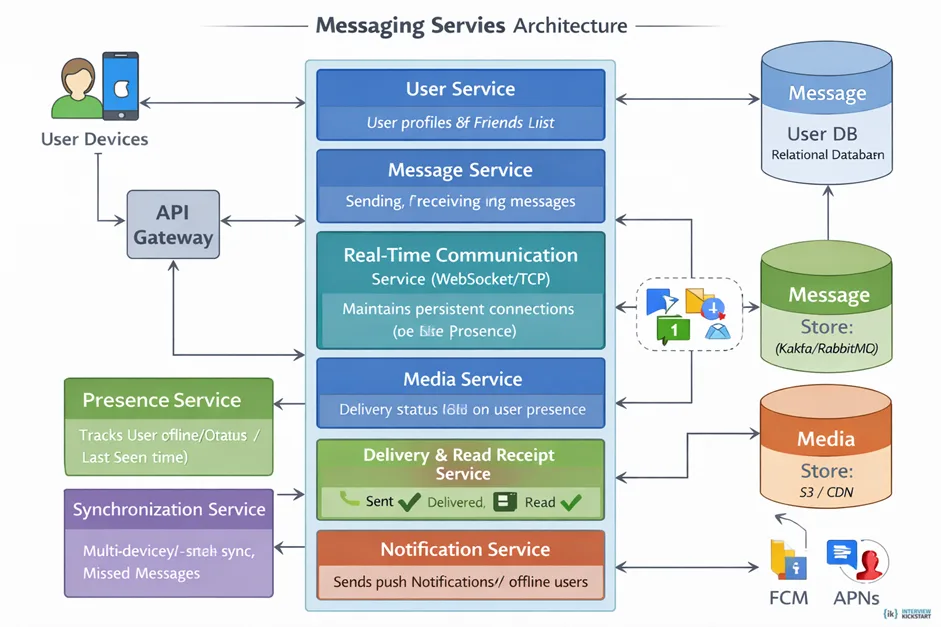
The key components of the messaging service, as detailed in the above diagram, are:
Q35. Design an API Rate Limiter
Clarifying questions for the interviewer:
Key components of the API rate limiter are:
The following table presents tips for system design interviews at Oracle, along with an explanation of why it matters for each tip.
| Tip | Why It Matters in System Design |
|---|---|
| Clarify scope first | Prevents wrong assumptions and overengineering. Helps you focus on the right problem (e.g., are you designing for 1K users or 10M users?). Shows structured thinking early and impresses |
| Estimate scale and storage needs | Drives all major decisions like database choice, caching, and partitioning. Without scale estimation, designs can be either inefficient or unable to handle the load. |
| Discuss trade-offs explicitly | There is no perfect system—only trade-offs. Demonstrating awareness (e.g., latency vs cost, consistency vs availability) shows senior-level thinking. |
| Cover SQL and NoSQL options | Shows flexibility in choosing the right data model. SQL is good for strong consistency and relationships; NoSQL is better for scalability and flexible schemas. |
| Explain availability vs consistency | Core distributed systems concept (CAP theorem). Helps justify design decisions like eventual consistency, replication, and failover strategies. |
Also Read: Top 50 Must-Know System Design Interview Questions (with Answers)
Oracle interview questions on behavior and leadership often are the bar raiser and determine your alignment with Oracle culture and values. The questions are answered with the STAR framework.
The following table presents a STAR framework answer for a database engineer for Oracle database optimization. Focus more on the action and results.
| STAR Component | What to Cover in your answer |
|---|---|
| Situation | Set context: In a DB team of 10, reporting queries on large Oracle tables took 20+ seconds |
| Task | Goal: Improve query performance for real-time dashboards |
| Action | Steps: Analyzed execution plans, created composite indexes. Used materialized views for aggregation and partitioned large tables. Rewrote queries using efficient joins |
| Result | Outcome: Query time reduced to <2 seconds- Dashboard achieved real-time. Improved user experience significantly |
Q36. Tell us about a challenging project you worked on.
In such questions, the interviewer is looking for problem-solving ability, technical depth, ownership, decision-making, and impact. Oracle wants to evaluate if you can handle real production problems at scale.
The following table presents an answer with the STAR framework for backend and Oracle DB developers.
| STAR Component | What to Say | Example Answer |
|---|---|---|
| Situation | What was the problem? | The speed of database queries was slow in peak usage, and took 15 seconds, causing API timeouts. |
| Task | What was your responsibility? | I was responsible for enhancing performance and system stability |
| Action | What did you do? (most important part) | Analyzed execution plans of slow queries and identified missing indexes. Optimized SQL joins and removed unnecessary data fetch. Also added caching with Redis and coordinated with the team to deploy changes safely |
| Result | What was the outcome? | Reduced query time from 15s to 2s. Improved API response time by 60%. The system handled the peak load without failures. |
Q37. How do you handle tight deadlines?
In Oracle interview questions, the interviewer is looking at how you set prioritization skills, decision-making under pressure, ownership, communication, and execution. Oracle wants to see if you can deliver important tasks on time.
A sample answer with the STAR framework is given below for an Oracle DB developer.
| STAR Component | What to Say | Example Answer (Backend / Database Scenario) |
|---|---|---|
| Situation | What was the context? | Key functionality had to be delivered in 3 days to resolve a production problem that the customer faced. |
| Task | Your responsibility | I had to prepare a tested, stable fix as per the deadline |
| Action | What you did (focus here) | Triaged tasks with impact vs effort. Focused on fixes that solved most user issues quickly. Identified non-critical features and de-scoped them. |
| Result | Outcome (quantify) | Selected a simple, reliable solution and worked on parallel tasks with the team (DB fix + API fix). |
Q38. Describe a time when you resolved a conflict in a team
In Oracle HR interview questions, the interviewers want to see emotional intelligence, a collaborative mindset, conflict resolution skills, communication clarity, and outcome focus. Avoid ‘I was right, and they were wrong’ narratives and understand the perspectives of others.
A sample answer with the STAR framework is given below for a software engineer.
| STAR Component | What to Say | Example Answer |
|---|---|---|
| Situation | Briefly describe the conflict, in a neutral stance, do not bale or take sides | In a project, a teammate and I did not agree on the system design approach. The issue was whether to use an RDBM or a NoSQL. |
| Task | Explain your responsibility in resolving it. | My objective was to select the right design, keep the project on track, and maintain team alignment. |
| Action | Show emotional intelligence: listening, understanding, collaboration. Avoid “I was right.” | I scheduled a discussion to understand their perspective first. They were focused on scalability, while I wanted data consistency. We listed requirements together and evaluated both approaches objectively. |
| Result | Focus on positive outcomes (team + project). | Based on our analysis, we agreed on a hybrid approach, using a relational database for transactions and NoSQL for high-volume data. |
Q39. How Do You Prioritize Multiple Tasks?
In such Oracle HR interview questions, the interviewer evaluates that you work on the right tasks first, justify tradeoffs, communicate when priorities shift, and remain focused under pressure.
I set priorities with an Impact vs Effort matrix. This framework helps to focus first on high-impact, low-effort tasks, then on high-impact, high-effort work. This helps to show that I am doing the work.
To meet deadlines, I make a trade-off by first delivering a draft version of the feature and taking up non-critical enhancements after the draft version is approved. This process is communicated to stakeholders.
Five tips to crack behavioral interview questions at Oracle are given in the following table.
| Tip | How to Apply |
|---|---|
| Use the STAR Framework | Where required, use the STAR framework to answer questions: Situation, Task, Action, Result. Keep it short, 2 minutes max. Focus on action and result. |
| Focus on Impact, Not Just Effort | Don’t just say what you did—explain why it mattered. Quantify results where possible (e.g., reduced latency by 30%, improved query time, avoided downtime). |
| Show Collaboration, Not Ego | Avoid “I proved them wrong.” Instead, say: “We aligned after discussing trade-offs.” Highlight listening, teamwork, and shared decision-making. |
| Explain Trade-offs Clearly | Oracle interviewers value decision-making. Mention what you chose, what you didn’t choose, and why (e.g., speed vs scalability, consistency vs performance). |
| Communicate Like an Engineer | Be structured and logical. Use phrases like: “I evaluated options based on X, Y, Z” or “I prioritized using impact vs effort.” It shows clarity and strong thinking. |
The blog, Oracle interview questions and answers (2026), presented several important Oracle interview questions and answers. Answers to Oracle questions asked in the interview covered several topics, such as the interview process, Oracle database, coding, system design, and behavioral.
Oracle interview questions and answers were given for freshers, intermediate, and experienced developers. The depth and intensity of the questions depend on your role and experience.
Prepare for questions asked in an Oracle interview by coding extensively in coding platforms, taking coding tests, and participating in mock interviews. Behavioral questions are also important. Reads books and watches podcasts on what Oracle tests in behavioral rounds.
Questions asked in an Oracle interview are challenging, but you can crack Oracle interview questions with smart preparation. Breadth and depth of responses are important for implementation and not memorization of theory. Trick or trap questions may be asked, and you should fully understand what is required and what they evaluate before answering. Oracle uses a balance of technical and behavioral skills for evaluation.
The Oracle interview process takes 3-6 weeks. It depends on their urgency to fill a role, the level at which you are under consideration, and the number of short-listed candidates.
Preparation for Oracle interview questions should cover data structure and algorithms, SQL and database, PL/SQL programming, performance tuning and optimization, system design, Python, and behavioral. The depth and intensity of coding and questions depend on your role and experience.
While Oracle seeks engineers with top skills, you must have several soft skills. These include easy adaptability, willingness to learn, and leadership. In senior roles, you should have demonstrated leadership and motivation skills.
Depending on the role and level, Oracle interviews are in 4 phases with several rounds in each. The technical assessment will have 3-4 rounds, and behavioral rounds.
Related Reads:


Time Zone:






Time Zone:
Time Zone: Asia/Kolkata
Time Zone: Asia/Kolkata
Hands-on AI/ML learning + interview prep to help you win
Explore your personalized path to AI/ML/Gen AI success

Time Zone: Asia/Kolkata
Hands-on AI/ML learning + interview prep to help you win
Time Zone: Asia/Kolkata
Hands-on AI/ML learning + interview prep to help you win
Explore your personalized path to AI/ML/Gen AI success



