Recursion is one of those topics that confuses a lot of programmers the first time they see it. They ask, is it a function that calls upon itself? Many think recursion looks like it would break everything. But once you get past the initial confusion, it starts to make sense, and you start seeing it everywhere. Tree traversal, graph exploration, backtracking, and recursion are quietly changing the way you use data structures and algorithms.
In this guide, we take you through what recursion actually is, how it works, the different forms it takes, how it performs against interaction, and when it actually makes sense to use it.
Recursion can be defined as a function that calls itself to solve a problem. It does not write in a loop, rather it handles one small piece of the problem at once and then hands the rest back to itself. This loop keeps on repeating till there is nothing left to solve.
There are two parts to every recursion: the base and recursive cases. The base case is the stopping condition. It is the point at which the function finally returns an answer without calling itself. On the other hand, the function calls itself with a simpler input, moving one step closer to the stopping point in the recursive case.
If the base case is not defined, then the function will crash by calling itself forever. Thus, it works cleanly and predictably without the base case.
A simple example of recursion is:
def factorial(n):
if n == 0: # base case
return 1
return n * factorial(n - 1) # recursive case
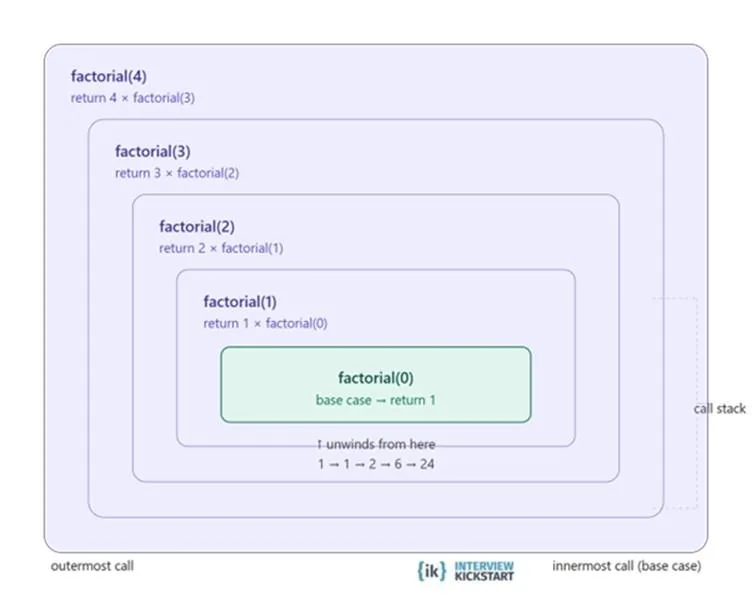
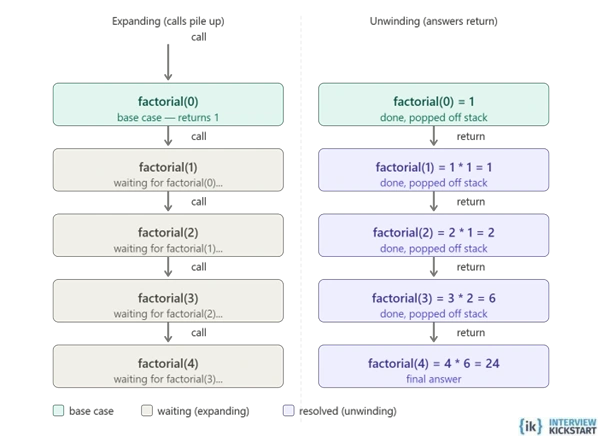
The above example calls factorial(4) which expands to 4 × 3 × 2 × 1 = 24. Each call waits for the one below it to return before it can finish, and this waiting is managed by the call stack.
Recursion can be understood with a simple everyday example. Imagine you are standing in a queue and want to know your position, but you cannot see how many people are ahead of you. So, you ask the person in front of you. That person also does not know and asks the next person ahead. This process continues until the person at the very front says, “I am number 1.”
The answer then travels back through the line, with each person adding 1 before passing it back. In recursive terms, every person represents a function call, the person at the front represents the base case, and the final answer returned through the queue represents the call stack unwinding. This same idea is used in programming problems like DFS traversal of a tree using recursion, where functions repeatedly call themselves until a stopping condition is reached.
To know how recursion works, an important point to remember is that in recursion, a function calls itself to solve a problem. Rather than using a loop to repeat an action, the function breaks a complex task down into smaller, simpler versions of the same task. The essential parts are:
How recursion works step by step; the system does not replace current tasks but stacks them when a function calls itself. The following stages are important:
Recursion example: calculate the factorial of 3 (3 × 2 × 1). The recursive rule applied is: factorial(n) = n × factorial(n-1). Base case: if n = 1, return 1.
| Step | Call | Action | Stack Status |
|---|---|---|---|
| 1 | fact(3) | Needs 3 * fact(2) | fact(3) is pushed |
| 2 | fact(2) | Needs 2 * fact(1) | fact(2) is pushed |
| 3 | fact(1) | Base Case! Returns 1 | fact(1) is popped |
| 4 | fact(2) | Receives 1, returns 2 * 1 = 2 | fact(2) is popped |
| 5 | fact(3) | Receives 2, returns 3 * 2 = 6 | fact(3) is popped |
The recursion stopping condition is called the base case and is critical for recursion in data structures. It is a condition within a recursive function that stops the function from calling itself further, to prevent infinite recursion and a potential stack overflow error.
It should be the simplest possible input that returns an answer directly without further recursion. If the function shrinks a number toward zero, stop at 0 or 1. If it consumes a list, stop when it is empty. If it traverses a tree, stop at None.
def factorial(n):
if n <= 1: # stop when n is 1 or 0
return 1
return n * factorial(n - 1)

The repeating step in recursion is the part that runs on every call except the base case. It calls itself with a simpler input, moving one step closer to the stopping condition.
def factorial(n):
if n <= 1: # stopping condition
return 1
return n * factorial(n - 1) # repeating step: same function, simpler input
# ^ do something ^ call self ^ reduce n by 1
The repeating step has three parts working together: the work (what to compute at this level – n *), the self-call (factorial(...) calling itself), and the reduction (n - 1, ensuring progress toward the base case).

Repeating a step in recursion is the part that runs on every function call except the base case. It works by calling itself with a simpler version of the problem, moving one step closer to the stopping condition each time. This is what makes recursion useful for breaking large problems into smaller and easier parts. A common example is how to reverse a stack using recursion, where the same function repeatedly processes smaller stack states until the stack is completely reversed.
There are two phases in the recursion process – an expansion phase and a finishing phase.
def factorial(n):
# Phase 1: Check
if n <= 1:
return 1 # base case, stop, return immediately
# Phase 2: Defer
return n * factorial(n - 1)
# ^ ^ ^
# the work self-call reduction (moves toward base case)
Fibonacci recursion diagram:
fibonacci(5)
├── fibonacci(4)
│ ├── fibonacci(3)
│ │ ├── fibonacci(2)
│ │ │ ├── fibonacci(1) → 1
│ │ │ └── fibonacci(0) → 0
│ │ └── fibonacci(1) → 1
│ └── fibonacci(2)
│ ├── fibonacci(1) → 1
│ └── fibonacci(0) → 0
└── fibonacci(3)
├── fibonacci(2)
│ ├── fibonacci(1) → 1
│ └── fibonacci(0) → 0
└── fibonacci(1) → 1
Every recursive function, regardless of the problem it is solving, follows the same basic patterns. There is always a condition that stops the recursive process, and there is always a step that calls the function. The recursion function works when both the base and recursive cases work together.
Progress is another element of the recursive process, but it is overlooked often. Each recursive call moves closer to the base case. If there is no change in the input, the function loops forever. But if it shrinks with every call, the function will eventually stop.
def recursive_function(input):
if base_condition:
return base_value # Stop recursion
return recursive_function(smaller_input) # Recursive call

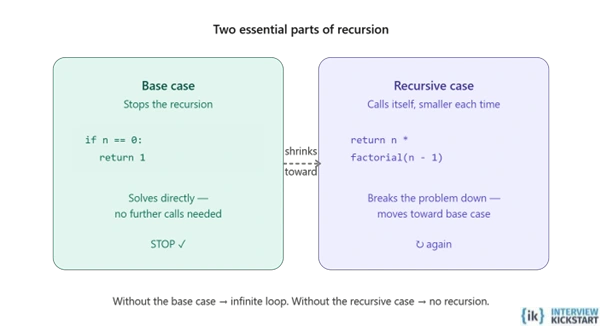
To know what recursion is, it is essential to know the two parts of recursion:
def factorial(n):
# Base case: stop here
if n == 0:
return 1
# Recursive case: call itself with a smaller problem
return n * factorial(n - 1)
There are two phases in the recursion process:
Expansion Phase:
Base Case – The Finishing Point:
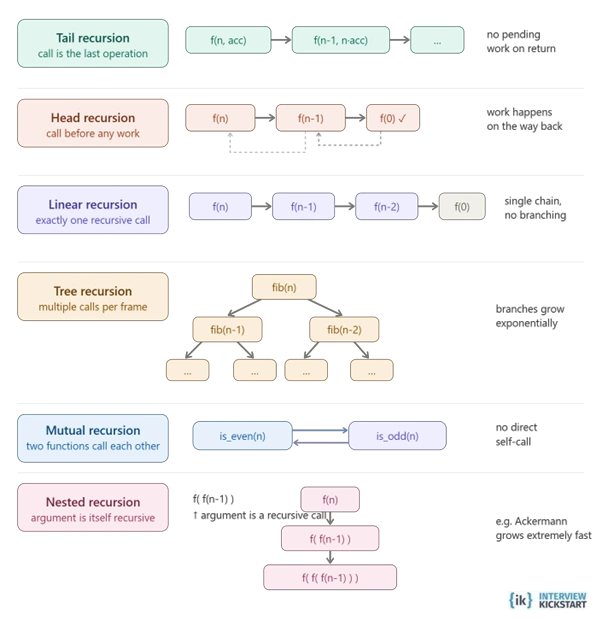
There are several important types of recursion that help explain how recursion works, illustrated through practical examples such as tail recursion, head recursion, linear, nested, and tree recursion.
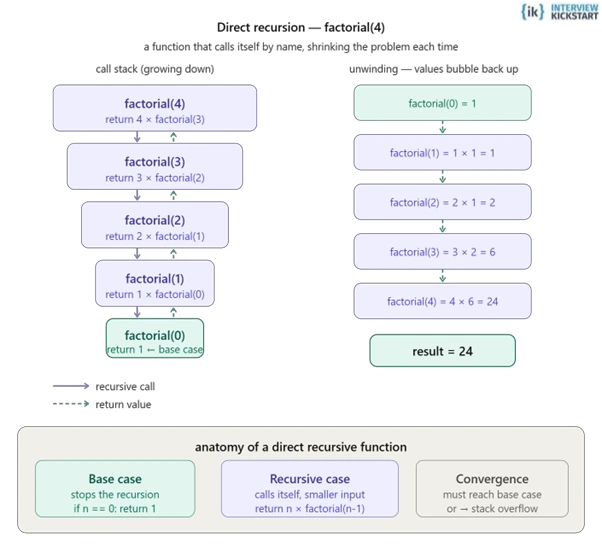
Direct recursion is when a function calls itself directly within the body to solve smaller subproblems. It is the simplest form of recursion. It requires a base case to terminate and is used in algorithms like factorial calculation.
The following C code snippet implements a simple recursive function named count, which prints integers from n down to 1:
void count(int n) {
if (n == 0) return; // Base case
printf("%d ", n);
count(n - 1); // Direct recursive call
}
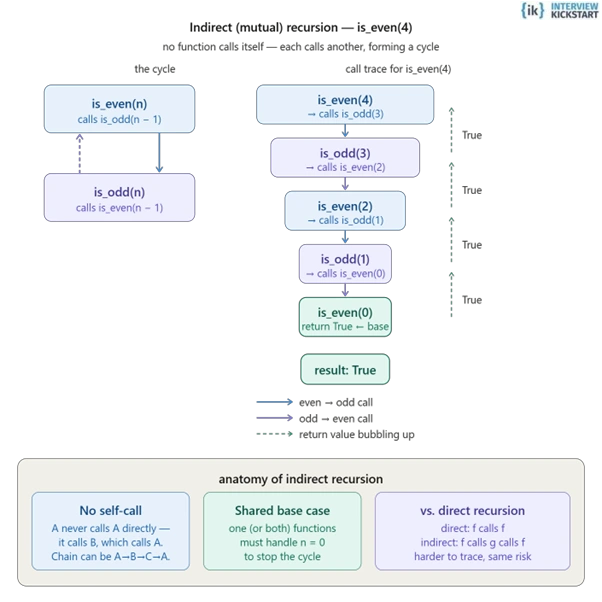
Indirect recursion, or mutual recursion, is when a function does not call itself directly. The recursive behavior appears from a chain of function calls with two or more different functions that eventually loop back to the original function.
def is_even(n):
if n == 0:
return True
return is_odd(n - 1) # calls is_odd, not itself
def is_odd(n):
if n == 0:
return False
return is_even(n - 1) # calls is_even, not itself
print(is_even(4)) # True
print(is_odd(3)) # True
In tail recursion, the recursive call is the final operation in a function, with all calculations already done. This is important in recursion in data structures because it allows compilers to perform tail call optimization, reusing the current stack frame instead of creating new ones. This prevents stack overflow errors and improves efficiency.
# non-tail: factorial(5)
# 5 * factorial(4)
# 4 * factorial(3)
# 3 * factorial(2)
# 2 * factorial(1)
# 1 * factorial(0) → 1
# unwinds: 1→1→2→6→24→120
# tail: factorial(5, 1)
# factorial(4, 5)
# factorial(3, 20)
# factorial(2, 60)
# factorial(1, 120)
# factorial(0, 120) → 120 (no unwinding needed)
Recursion and iteration are two methods for repeatedly running instructions. The control structures and performance differ significantly. A recursion example is the Fibonacci numbers calculated by adding the two previous numbers, expressed as fib(n) = fib(n-1) + fib(n-2). An iteration example is a loop that checks each item in a list sequentially to find a target value.
The table presents differences between recursion and iteration.
| Aspect | Recursion | Iteration |
|---|---|---|
| Definition | Function calls itself | Loop repeats a block |
| Termination | Base case | Loop condition (while, for) |
| State | Carried on the call stack | Carried in variables |
| Stack usage | O(n) frames (unless TCO) | O(1); no stack growth |
| Readability | Natural for trees, graphs, and divide-and-conquer | Natural for sequences, counters, and accumulators |
| Speed | Slower; function call overhead per step | Faster; no call overhead |
| Risk | Stack overflow on deep input | Infinite loop if condition is never false |
| Debugging | Harder: must trace the call stack | Easier; state is explicit in variables |
| Code length | Often shorter and closer to the math | Often longer but more explicit |
| Best used for | Trees, graphs, backtracking, and divide-and-conquer | Arrays, counters, simple repetition |
| Languages that prefer it | Haskell, Erlang, Scheme, Prolog | Python, Java, C, JavaScript (in practice) |
| Convertible? | Any recursion can be converted to iteration (using an explicit stack) | Any iteration can be expressed as tail recursion |
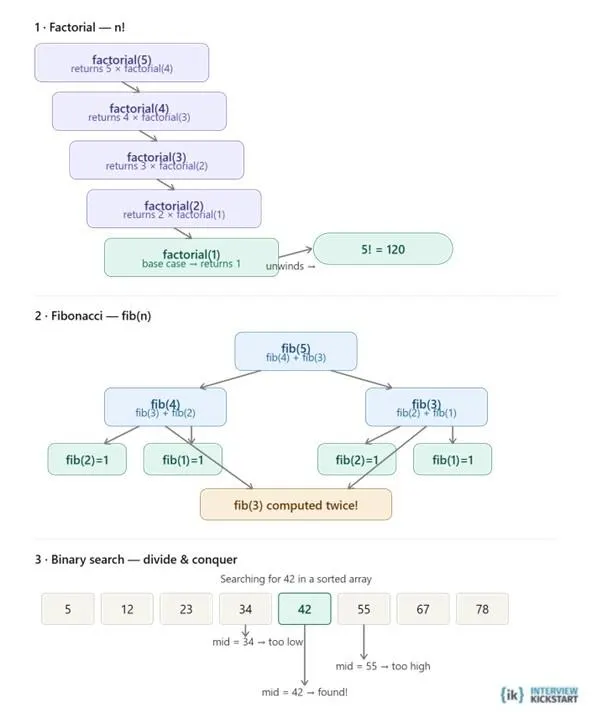
Common recursion examples help explain how recursive thinking works in programming. Problems like factorials, Fibonacci sequence, binary search, and DFS traversal of a tree using recursion are widely used to demonstrate how a function repeatedly solves smaller versions of the same problem until it reaches a stopping condition.
Factorial is often called the “hello world” of recursion because it clearly shows how a function keeps calling itself with a smaller input until it reaches the base case where n = 1. Each function call waits on the call stack until the deepest call finishes, and then the results return step by step.
Fibonacci is an example of branching recursion where each function call creates two additional calls. This makes it easy to understand recursion trees, but it also highlights inefficiency because the same values, like fib(3), are calculated multiple times. That is why optimized solutions often use memoization to store already calculated results.
Binary search demonstrates divide-and-conquer recursion. Instead of checking every element one by one, the algorithm repeatedly cuts the search space in half and recursively searches only the relevant section until the target value is found or the range becomes empty.
Factorial is the “hello world” of recursion, a function that calls itself with a smaller input until it hits the base case (n = 1). Each call sits on the call stack waiting until the deepest call returns, then the results unwind back up.
Fibonacci is a branching recursion where each call spawns two more. The tree diagram reveals the key inefficiency: fib(3) gets computed twice. This is why real implementations use memoization caching results to avoid redundant work.
Binary search is a divide-and-conquer recursion. It narrows the search space in half each time. Instead of looping through the array, it recursively searches only the relevant half until it either finds the target or exhausts the range.
Recursion provides high code readability and is ideal for hierarchical problems in data structures like trees or the DOM. However, it requires significant performance tradeoffs compared to iteration, due to higher memory usage and execution time overhead.
Time Complexity Analysis:
Recursion provides concise and readable code by breaking complex problems into smaller, manageable subproblems. The process makes it suitable for traversing nested structures like trees and graphs, which is why it is widely used in recursion in data structures. It reduces complex, messy iterative loops, making it easier to solve problems like sorting and traversing.
One of recursion’s biggest strengths is that it lets you focus on one step at a time. You define what needs to happen at a single level, and the function takes care of repeating that logic until the problem is fully solved. This makes the code shorter and often much easier to follow.
Take the factorial of a number. Mathematically, 4! is just 4 × 3!, and 3! is just 3 × 2!. Recursion mirrors that logic directly. You describe the pattern once, and the rest follows naturally.
Compared to manually tracking a running total inside a loop, this version reads almost like the mathematical definition itself.
Not every problem suits recursion, but some problems are recursive by nature; meaning the problem is made up of smaller versions of itself. In those cases, recursion fits the shape of the problem so well that an iterative approach would only make things more complicated.
Recursion tends to be the natural choice when traversing a file system where each folder can contain more folders, navigating trees or graphs where each node connects to more nodes, solving backtracking problems like mazes or puzzles where you explore one path and backtrack if it fails, and implementing divide-and-conquer algorithms like merge sort or binary search where the input is split in half with each step. In all of these scenarios, recursion keeps the code clean and aligned with how the problem actually works.

Recursive functions often have problems of high memory consumption due to stack overhead, leading to stack overflow errors. This highlights limitations when understanding ‘what is recursion, analyzing how recursion works, and applying it in data structures, even with common recursion examples.
Execution speeds are slower compared to iteration, and there is increased complexity in debugging or tracing, as seen in many recursion examples.
Every recursive function needs a base case; a condition that tells it when to stop. Without one, the function keeps calling itself indefinitely, the call stack fills up, and the program crashes with a stack overflow error. This is one of the most common mistakes when writing recursive code.
Here is what that looks like when the base case is missing:
# No base case - runs forever and crashes
def countdown(n):
print(n)
countdown(n - 1)
And here is the corrected version with a proper stopping condition:
# Base case included - stops correctly at 0
def countdown(n):
if n == 0: # base case
return
print(n)
countdown(n - 1)
The fix is simple, but forgetting it is an easy mistake to make, especially in more complex recursive logic.
Recursion is not free. Every time a function calls itself, the program sets aside memory to store that call, its variables, its position in the code, and where to return once it finishes. These stack frames pile up until the base case is reached, and only then does the memory start to free up.
For small inputs this is rarely an issue. But for deep recursion say, calculating factorial(10000), the program creates 10,000 stack frames in memory simultaneously. An iterative version of the same function would use a single variable and a loop, with virtually no memory overhead. For performance-sensitive applications or large inputs, that difference matters.

Recursion is used to solve complex problems that can be broken down into smaller, identical subproblems. It is widely applied when navigating nested structures, branching paths, and implementing divide-and-conquer algorithms. It is frequently used in traversing trees and graphs, file system navigation, quicksort, merge sort, and AI search problems.
Most candidates prepare in isolation and then get blindsided in real interviews. The Technical Mock Interviews program by Interview Kickstart puts you in live, realistic interview settings with hiring managers from top tech companies. You’ll practice coding, system design, and domain-specific questions while receiving structured feedback and 1:1 coaching to improve with every session.
Beyond technical skills, you’ll learn how to communicate clearly, think under pressure, and approach problems the way top companies expect. With guided practice and targeted insights, you’ll refine both your strategy and confidence. If you want your real interview to feel familiar instead of overwhelming, this is where that shift happens.
Recursion is one of those concepts that clicks differently once you have seen it in action a few times. It can feel counterintuitive at first, a function solving a problem by handing a smaller version of that same problem back to itself, but that is precisely what makes it so powerful for the right situations.
Understanding recursion means understanding its two non-negotiable parts: a base case that knows when to stop, and a recursive case that makes steady progress toward that stop. Get those right, and recursion handles the rest. Get them wrong, and your call stack will let you know.
Use recursion when the problem is naturally hierarchical, such as trees, graphs, divide-and-conquer algorithms, and backtracking. Reach for iteration when raw speed and memory efficiency matter more. Most real-world programming involves knowing which tool fits the job, and recursion is an important one to have full command of.
A stopping condition or base case is important in recursion because it tells the function when to stop calling itself. Without a stopping condition, the function would call itself forever, leading to infinite recursion and stack overflow.
If recursion never stops, it leads to infinite recursion. The function keeps calling itself repeatedly, the call stack keeps growing, and the memory runs out, resulting in a crash.
Not always. Recursion is best for trees, divide-and-conquer problems, and backtracking. Use recursion when it simplifies the problem, but prefer iteration when efficiency is critical or when the recursion depth may be very large.
Recommended Reads:






Time Zone:
Time Zone: Asia/Kolkata
Time Zone: Asia/Kolkata
Hands-on AI/ML learning + interview prep to help you win
Explore your personalized path to AI/ML/Gen AI success

Time Zone: Asia/Kolkata
Hands-on AI/ML learning + interview prep to help you win
Time Zone: Asia/Kolkata
Hands-on AI/ML learning + interview prep to help you win
Explore your personalized path to AI/ML/Gen AI success



