Mean Squared Error is considered a strong and comprehensive tool that helps people measure, monitor, and consider the statistical model’s performance. It is a common metric used to evaluate the performance of a regression model in machine learning.
In the statistics and data analysis industry, understanding the accuracy of our models and predictions is very important. These models enable people to learn from the data and provide sufficient estimations.
Mean Squared Error (MSE) is a benchmark in statistical analysis, providing a measure of the quality of an estimator or predictor. Unlike other error metrics, such as Mean Absolute Error (MAE), MSE penalizes larger errors more heavily due to its squaring operation.
This property makes it particularly useful in scenarios where precise estimation is crucial.
Read More: Linear Regression in Machine Learning
If you want to know what type of ML questions are asked at FAANG+ companies, you should watch the video below. Alternatively, you can look at our ML Interview Masterclass course that prepares you for your next challenging ML interviews.
What Is Mean Squared Error?

Mean Squared Error (MSE) is a risk function that calculates the mean of the squared difference between the observed values and the predicted values.
It is an elementary statistic that helps identify how close the statistical model’s predictions are. The lower the Mean Squared Error value, the better.
Minimizing the MSE during model training ensures that the predictions are as accurate as possible, enhancing the model’s effectiveness in making reliable predictions.
Mean Squared Error Formula
The following is the formula of MSE:
MSE = Σ(yi – pi)² / n
Here,
- yi represents the ith observed value.
- pi represents the corresponding predicted value for yi.
- Σ signifies the summation performed over all data points (from i = 1 to n).
- n denotes the total number of observations in the data set.
Mean Squared Error Examples
Let’s consider a scenario where we’re building a model to predict house prices based on square footage. Here’s an example:
Here, we calculate the squared errors for each house and then sum them. Finally, dividing the sum by the number of houses (n = 3) gives us the Mean Squared Error.
MSE = (2500 + 100 + 40000) / 3 = 42666.67
A lower MSE in this case indicates a model that makes predictions closer to the actual house prices.
Mean Squared Error: Concepts
Here are some concepts related to Mean Squared Error:
- Root Mean Squared Error (RMSE): Root Mean Squared Error (RMSE) is the square root of the Mean Squared Error. It helps to measure the magnitude of the error because RMSE is in the same units.
- Variance: MSE incorporates both the variance and the square of the bias of the estimator. If an estimator is unbiased, then the MSE is simply equal to the variance.
- Loss Function: MSE is a specific type of loss function used to quantify the difference between the predicted values and the actual ones.
By minimizing the loss function during model training, it is possible to help the model learn from the data and make more accurate predictions in the future.
Mean Squared Error Applications

In addition to the mentioned central applications, the Mean Squared Error has several worthwhile applications in various contexts:
- Model Selection: MSE is commonly used to evaluate the performance of regression models.
Therefore, the model that minimizes this measure will usually be chosen because it best fits data from training samples and thus is likely to make the most accurate predictions for new ones also. - Hyperparameter Tuning: Most models can adjust certain parameters by hand, not determined through backpropagation.
It is important to explore how different values for these hyperparameters affect the model’s performance. It is often able to give the first sign so that when judging the effects of various hyperparameter values MSE can provide this.
- Regression Diagnostics: In regression analysis, a high mean squared error could signal something wrong with one’s model.
Examining the joint distribution of squared errors in machine learning can reveal patterns like heteroscedasticity (varying error spread) or nonlinearity (deviation from linear relationships) that the current model fails to capture.
- Signal Processing: In signal filtering and denoising, the square of the error is used as an objective criterion to minimize.
How this technique can purify signals is as follows: by one means or another, these techniques eliminate noise in a signal and try to keep as much as possible from its original form. - Image Reconstruction: Compression trades off between quality and achievability. The MSE assesses how well image reconstructions that have been compressed can provide the original.
A reduced MSE value represents images that more closely match other sourced media files formed using certain techniques. - Financial Modeling: Financial predictions from stock prices, futures market trends, and portfolio performance have models.
The MSE tracks the accuracy of the input models. The smaller the error, the more accurate the models are updated for reliability, as reflected in investment decisions.
Common Mistakes and Pitfalls While Calculating Mean Squared Error
While Mean Squared Error is a valuable performance metric, several reasons can lead to deceptive conclusions. Here are the most common mistakes and pitfalls that should be avoided:
- Scale-dependent
As we have already mentioned, MSE is correlated with the scale of the data. In this case, let us look at the example of the data that is used for predicting house prices. If the data is in dollars, a low MSE indicates that your model performs well. However, if the price data are in cents and thus are 100 times smaller than dollars, the MSE for the same prediction’s correctness will be 10,000 times greater, which is rather misleading, especially for a comparison of different models of the same problem, but with different scales of input data. The possible solution is the following:
- Standardization or normalization: These approaches imply that the data for the variables would be in a similar range and scale. This way, the MSE comparison between two models can be viewed as fair.
- Root Mean Squared Error (RMSE): RMSE allows representing MSE in the original data units. While it is not a complete solution, RMSE will provide more understandable information about the error size than its squared number.
- Doesn’t account for outliers
When it comes to data, outliers are the numbers that significantly differentiate from most of the data that my model uses for making predictions. Since MSE uses squared mistakes, it prioritizes the outliers. Hence, if there are just a few extra points, the modeling outcomes can be distorted. Even though the MSE value can be low, it does not mean that the data trend is discovered since it’s “distracted” by the work with outliers. Here’s the solutions for the same:
- Robust Loss Functions: You can consider other loss functions that are not outlier-sensitive. An example would be Mean Absolute Error: the average difference between the prediction and observation absolute values.
- Outliers Detection: You can also use the Interquartile Range method to detect the outliers. Depending on the possible correlations and explanations, you can decide whether to simply remove them or work with them using winsorization.
- Directionally-unaware
The third most common mistake is being indifferent to the direction of the error. Low MSE does not imply that the model is unbiased. Analyzing the residuals’ direction, its positivity/negativity can identify the signs. Here’s the solution to this:
- Residual Analysis: You can use the plot with residuals to understand the biases.
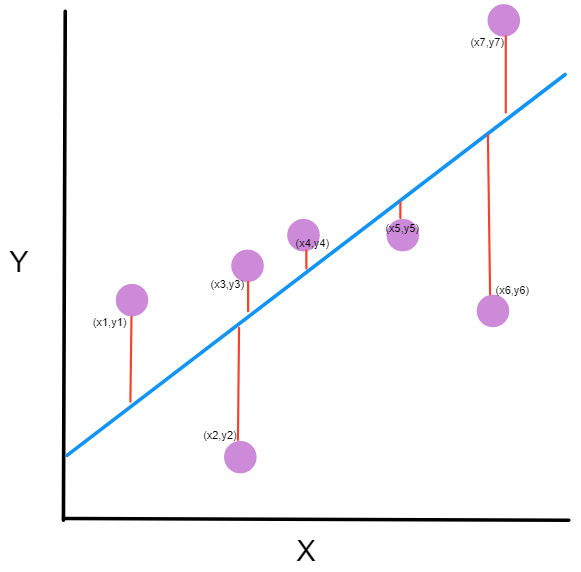
- X-Y Scatter: The plot will show the difference between the target data points and their predicted values.
Calculate Mean Squared Error Using Excel
Excel provides a straightforward way to calculate Mean Squared Error (MSE). Here’s a breakdown of the steps:
- Organize Your Data: Enter your actual values (observed data points) in one column and the corresponding predicted values (generated by your model) in another adjacent column.
- Calculate Squared Errors: In a third column, compute the squared difference between each corresponding actual and predicted value. You can use the formula (actual value – predicted value)^2 or Excel’s built-in power function ^ to square the differences.
- Find the Average Squared Error: Use the AVERAGE function to calculate the mean of the squared errors in the third column. This will directly give you the MSE value.
Example
Assuming your observed data is in column A and predicted values are in column B, you can enter the following formula in cell C2 (assuming you have data starting from row 2) and copy it down for all data points:
=POWER(A2-B2,2)
This calculates the squared error for the first data point.
In another cell (let’s say D2), use the following formula to find the MSE:
=AVERAGE(C2:C<number of data points>)
Replace <number of data points> with the actual number of rows containing squared errors (which is the same as the number of data points).
FAQs: Mean Squared Error
What does squared error tell us?
MSE tells us how well a model’s predictions fit the actual data. A lower MSE indicates a better fit, signifying predictions closer to observations.
Is a higher or lower MSE better?
A lower MSE is always preferred. It suggests the model’s predictions are, on average, closer to the actual values.
What is a good MSE value?
There’s no universal “good” value for MSE. It depends on the scale of your data and the specific problem you’re addressing. A lower MSE relative to the range of your data points is generally desirable.
Which is the best MSE or RMSE?
MSE is in squared units, while Root Mean Squared Error (RMSE) is the square root of MSE.
RMSE brings the error back to the original scale of your data, making it easier to interpret the magnitude of the error. Both provide valuable insights, but RMSE might be preferred for easier interpretation.
What is better than MSE?
In some cases, other loss functions might be better suited than MSE. For instance, if outliers heavily influence your data, using a robust loss function less sensitive to outliers might be beneficial.
Can MSE be negative?
No, MSE cannot be negative. Squaring the errors in the formula ensures a non-negative value.
Is MSE a good loss function?
MSE is a widely used and effective loss function, particularly for regression problems. However, its limitations, like scale dependence and outlier sensitivity, should be considered when choosing a loss function for your specific task.












