A tree is a non-linear data structure, which consists of nodes and edges that represent a hierarchical structure. It is a connected graph with no cycles. A tree with “n” nodes should always contain “n-1” edges.
Tree traversal is one of the most basic requirements for dealing with different types of tree
problems. Tree traversal refers to the process of visiting each node of the tree and updating the node if required.
Learning about trees is a must for software engineers as trees are frequently used in computer science fields such as XML parsers, databases, domain name explorers, and many other fields. Problems on trees are often asked in technical interviews and coding rounds of FAANG companies and other tier-1 tech companies.
To help you in your prep, we’ll cover the following topics in this article:
What Is Depth-First Search or DFS?
n Ary-Tree Traversals Through DFS Using Recursion
DFS Traversal of a Tree vs. Graph
Binary Tree Traversals Through DFS Using Recursion
Time Complexity of DFS Traversal of a Tree
Auxiliary Space Used by DFS Traversal of a Tree
Strengths and Weaknesses of DFS Traversal of a Tree
Problems on DFS Traversal of a Tree
FAQs on DFS Traversal of a Tree
What Is Depth-First Search or DFS?
The depth-first search algorithm is used for traversing or searching a tree or any other graph data structure. The key idea behind DFS is backtracking. Let’s understand with the help of an example.
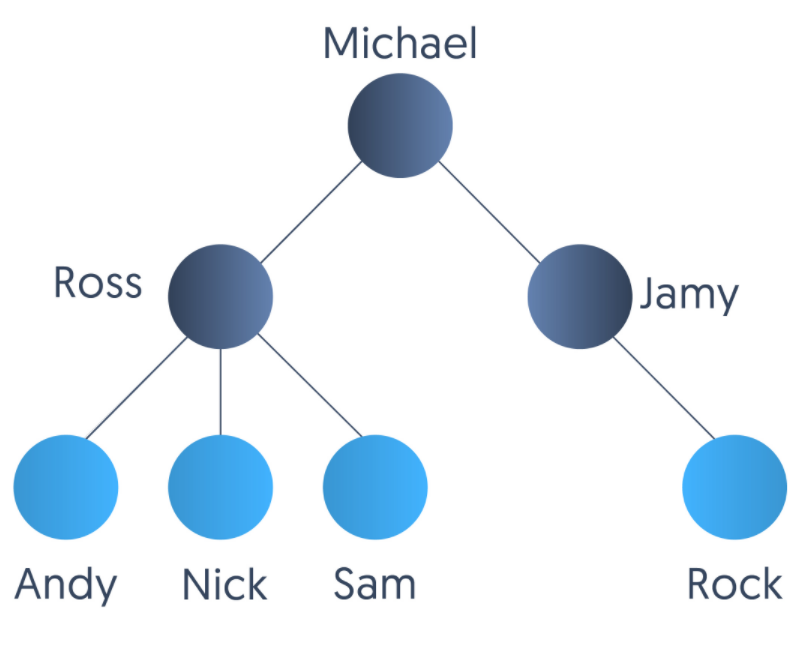
A family tree is an example of a tree representing parent-child relationships. Let’s say we have been given a family tree, and we need to return the number of children in the family.
Definitions:
Root: The node at the top of the tree is called the root node. Every tree has a single root node.
Parent: The node which is a predecessor of any node is called a parent node.
Child: The node which is the descendant of any node is called a child node.
Leaf: The node which does not have any child node is called the leaf node.
Here’s what we see in the image:
“Michael” is the root node. He is a parent to “Ross” and “Jamy” and a grandparent to “Andy,” “Nick,” “Sam,” and “Rock.” In tree dynamics, we call it the root node.
“Ross” is a parent of “Andy,” “Nick,” and “Sam.”
“Jamy” is a parent to “Rock.”
All nodes in purple color are leaf nodes. In tree data structures, we call them the leaf nodes.
All nodes of a tree will contain some information. Here, they contain the name of the person.
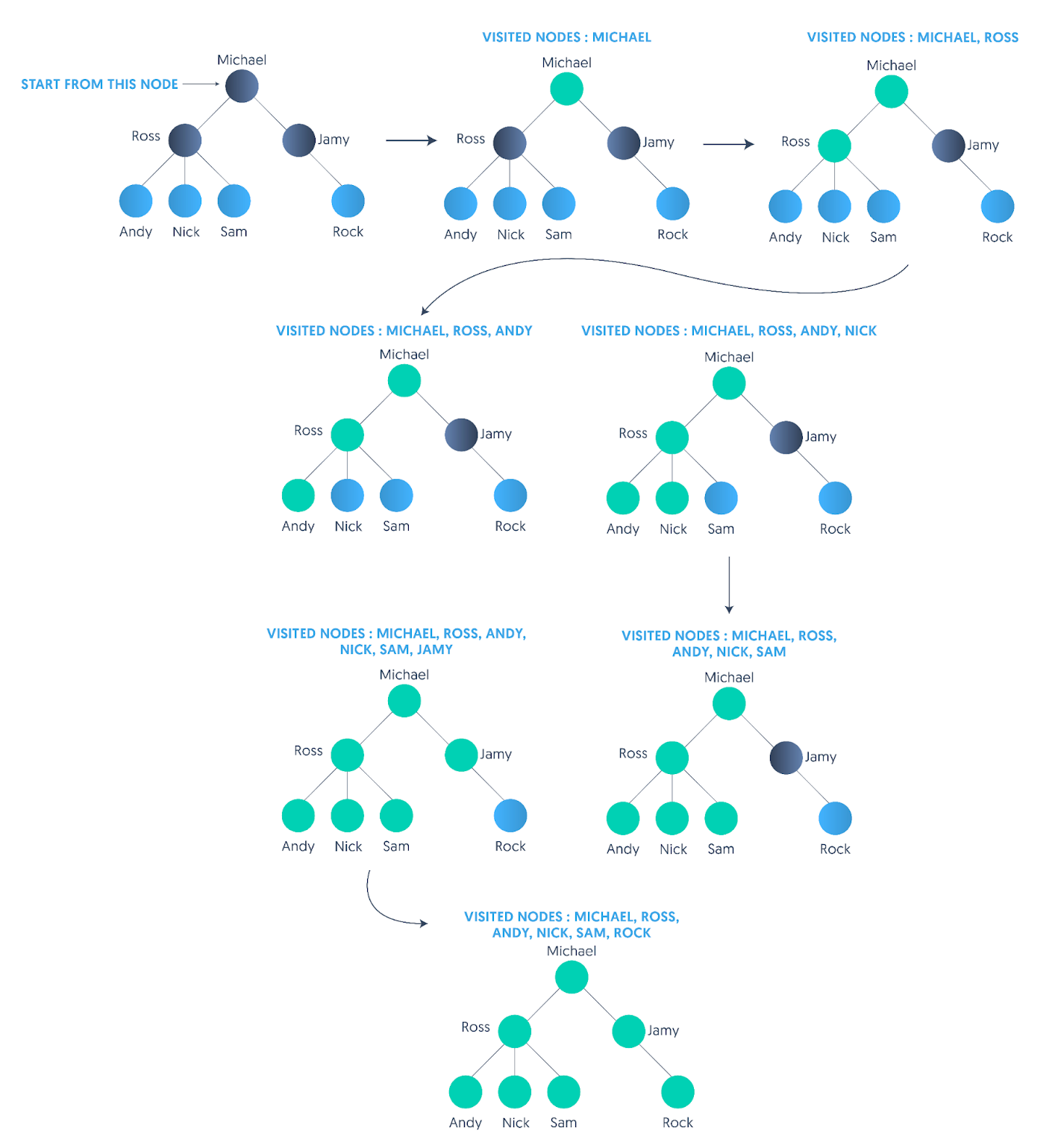
Our problem statement is counting the number of leaf nodes in the above tree. Let's say we start with the root node, “Michael,” in our case.
“Michael” has two child nodes, and hence, it can’t be a leaf node.
Next, we go to one of its children. We go to “Ross.” “Ross” also contains three children. So, it can’t be a leaf.
Going to the children of “Ross.” Suppose we go to “Andy” — does not contain any children, and we know that “Andy” is a leaf node.
We now backtrack to our parent node “Ross” and find that there are other children of “Ross.” that we have not visited yet. So, we visit the next unvisited child, “Nick,” in our case and find that it's also a leaf node. We backtrack again, and this continues until we have visited all nodes of the tree in the process.
So the key idea is to visit the child of the current node until we reach a leaf node, then we backtrack and repeat the process for the next child node, which is not visited yet. This is depth-first traversal. Always start from an arbitrary node and go as deep as possible along each branch one after another before backtracking.
n Ary-Tree Traversals Through DFS Using Recursion
An n-ary tree is a tree that allows us to have “n” number of children of a particular node. Hence the name n-ary. Let’s see how to traverse this tree using DFS.
DFS Traversal of a Rooted Tree Using Visited Array
The algorithm starts at the root node, marks it as visited, explores any adjacent unvisited node, and continues this process until no unvisited nodes are left. Then, it backtracks to the previous nodes and checks again for any unvisited node. This process is continued until no unvisited node is left in the tree.
For the recursive DFS traversal on a tree, we don’t need to maintain track of visited nodes as a tree does not contain any cycle. We can just keep track of the parent node of the current node so that we don’t visit the node’s parent as it is already visited. This approach will be discussed in detail in the next section.
The DFS traversal can be implemented either recursively or non-recursively. The recursive implementation uses the call stack, while the iterative traversal uses a user-defined stack.
Pseudocode for DFS Traversal of a Rooted Tree Using Visited Array
Let T denote the tree. The following pseudocode describes the recursive implementation of DFS traversal on a tree.
DFS(T, u)
visited[u] = true
for each v ∈ T.Adj[u]
if visited[v] == false
DFS(T,v)
init() {
For each v ∈ T
visited[v] = false
//u denotes the root node
//if root node is not defined, we can select any
//arbitrary node as root node
DFS(T, u)
}
DFS Traversal of a Rooted Tree Without Visited Array
We know that in a tree data structure, we cannot have cycles. This idea will be used here.
We keep track of the parent node and the current node while calling the DFS function. We always want to go down the depth until all of the current node’s children are visited and then backtrack to its parent. We never want to go to the parent node at an intermediate step when some children remain unvisited for the current node.
Pseudocode for DFS Traversal of a Rooted Tree Without Visited Array
DFS(T, u , parent)
for each v ∈ T.Adj[u]
if v != parent
// for node v its parent is u and this information
// is passed in dfs
DFS(T, v , u)
init() {
//u denotes the root node
//if root node is not defined, we can select any
//arbitrary node as root node
//since root cannot have a parent so we pass -1 as its parent
DFS(T, u , -1)
}
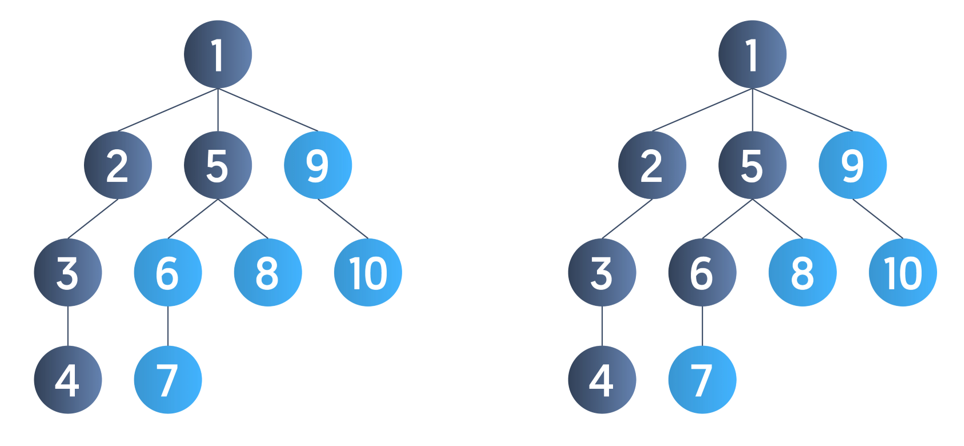
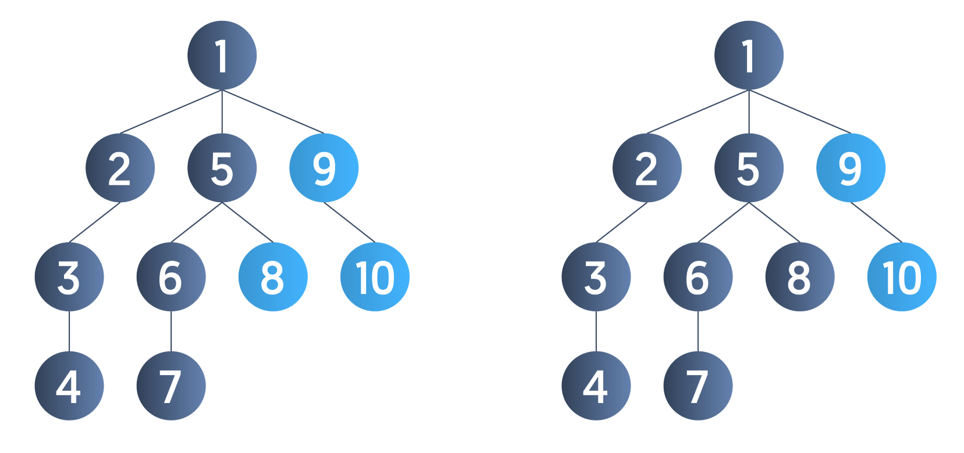
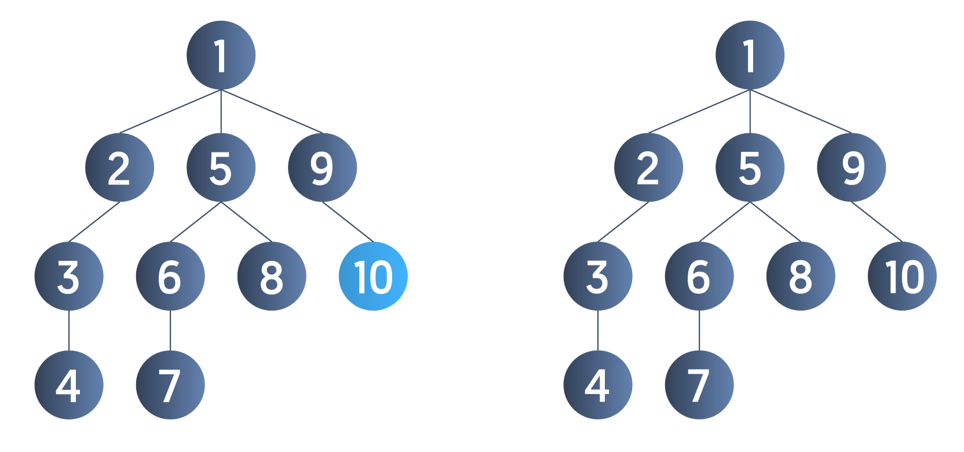
For example, consider the tree below. Suppose we select 1 as the tree’s root node and call DFS(1); the figures below simulate the order in which the nodes are visited.
First, the DFS(1) is called. We pick any one of the adjacent unvisited nodes of node 1. Suppose we pick node 2 and hence call DFS(2). The DFS(2) calls DFS(3), which in turn calls DFS(4). Once we reach node 4, there is no adjacent unvisited node. Hence, we backtrack to node 3. Here too, there is no adjacent unvisited node, so we backtrack again to node 2, then node 1.
Once we reach node 1, we pick node 5 and explore this branch as deeply as possible before backtracking. Similarly, we continue this process until no unvisited node is left in the tree.
Hence, one of the DFS traversals is:
Note: The order of visiting adjacent nodes does not matter in the case of DFS traversal. There can be many possible DFS traversals of the above tree, such as 1,5,6,7,8,9,10,2,3,4 or 1,5,6,7,8,2,3,4,9,10.
Depth-First Search Traversal of a Tree vs. Graph
Tree traversal is itself a form of graph traversal. The depth-first search traversal on a graph is very similar to the depth-first search on a tree. The main difference between the two traversals lies in the fact that the tree is itself a special type of connected graph with no cycles.
Hence, in the case of DFS traversal on a graph, we require additional memory to store the visited nodes so that we don’t visit them again. The graph can have cycles and may not be connected, so we need to keep track of visited nodes.
Binary Tree Traversals Through DFS Using Recursion
Based on the order of visiting the nodes, DFS traversal on a binary tree can be divided into the following three types: Inorder traversal, preorder traversal, and postorder traversal.
1. Inorder Traversal
Recursively traverse the left subtree of the current node.
Access the data of the current node.
Recursively traverse the right subtree of the current node.
Example:
Implementation in C++:
#include <iostream>
using namespace std;
//each node of the binary tree has a data , pointer to the left and
//the right child
struct Node {
int data;
struct Node *left, *right;
Node(int data)
{
this->data = data;
left = right = NULL;
}
};
void inorderTraverse(struct Node* node)
{
if (node == NULL)
return;
/* first recur on left child */
inorderTraverse(node->left);
/* then access the data of current node */
cout << node->data << " ";
/* now recur on right child */
inorderTraverse(node->right);
}
int main() {
struct Node* root = new Node(1);
root->left = new Node(2);
root->left->left = new Node(3);
root->left->right = new Node(4);
root->right = new Node(5);
root->right->right = new Node(8);
root->right->left = new Node(6);
root->right->left->left = new Node(7);
inorderTraverse(root);
return 0;
}
Output:
3 2 4 1 7 6 5 8
Benefits of Inorder traversal
In a binary search tree, where for each node, the nodes in its left subtree are less than it, and the nodes in the right subtree are bigger than it, the inorder traversal allows us to access the elements in sorted order.
2. Preorder Traversal
Access the data of the current node.
Recursively traverse the left subtree of the current node.
Recursively traverse the right subtree of the current node.
Example:
Implementation in C++:
#include <iostream>
using namespace std;
//each node of the binary tree has a data , pointer to the left and
//the right child
struct Node {
int data;
struct Node *left, *right;
Node(int data)
{
this->data = data;
left = right = NULL;
}
};
void preorderTraverse(struct Node* node)
{
if (node == NULL)
return;
/* access the data of current node */
cout << node->data << " ";
/* then recur on left child */
preorderTraverse(node->left);
/* now recur on right child */
preorderTraverse(node->right);
}
int main() {
struct Node* root = new Node(1);
root->left = new Node(2);
root->left->left = new Node(3);
root->left->right = new Node(4);
root->right = new Node(5);
root->right->right = new Node(8);
root->right->left = new Node(6);
root->right->left->left = new Node(7);
preorderTraverse(root);
return 0;
}
Output:
1 2 3 4 5 6 7 8
Benefits of Preorder
With the help of the preorder traversal of a binary search tree, we can reconstruct the tree back. Preorder traversal is used to get the prefix expression of an expression tree.
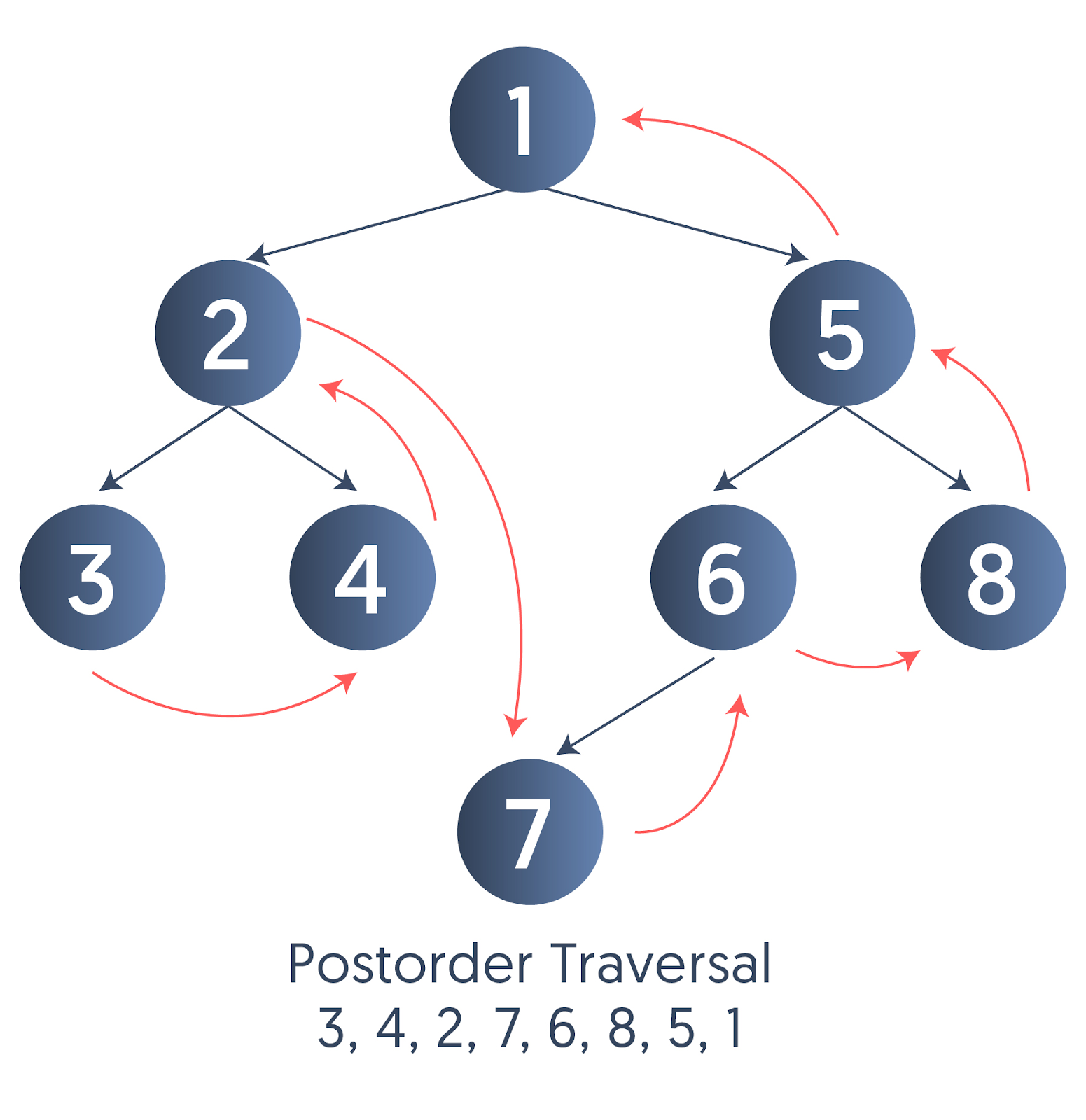
3. Postorder traversal
Recursively traverse the left subtree of the current node.
Recursively traverse the right subtree of the current node.
Access the data of the current node.
Example:
Implementation in C++:
#include <iostream>
using namespace std;
//each node of the binary tree has a data , pointer to the left and
//the right child
struct Node {
int data;
struct Node *left, *right;
Node(int data)
{
this->data = data;
left = right = NULL;
}
};
void postorderTraverse(struct Node* node)
{
if (node == NULL)
return;
/* first recur on left child */
postorderTraverse(node->left);
/* now recur on right child */
postorderTraverse(node->right);
/* then access the data of current node */
cout << node->data << " ";
}
int main() {
struct Node* root = new Node(1);
root->left = new Node(2);
root->left->left = new Node(3);
root->left->right = new Node(4);
root->right = new Node(5);
root->right->right = new Node(8);
root->right->left = new Node(6);
root->right->left->left = new Node(7);
postorderTraverse(root);
return 0;
}
Output:
3 4 2 7 6 8 5 1
Benefits of Postorder
With the help of postorder traversal of a binary search tree, we can reconstruct the tree back.
Postorder traversal is also used to convert the postfix expression to an expression tree.
Time Complexity of DFS Traversal of a Tree
The time complexity can be calculated from the number of nodes visited in the traversal of the tree. First, we analyze the inorder traversal function on a binary tree. By breaking down our function, we can see that for each time the function is called, these four steps occur:
Checking if the node is null
Recur on the left subtree
Accessing the data of the current node
Recur on the right subtree
For each call of the function, a maximum of four operations are performed, and this function can be called only one time for each node of the tree.
If we consider the number of nodes in the tree to be n, approximately 4*n operations will be performed. This bound remains the same for the inorder, preorder, and postorder traversal. Hence, the time complexity in terms of Big-O is O(n) for each of the traversal techniques.
Now, let us consider an n-ary tree.We visit all the nodes during the DFS traversal, and hence, the time complexity is O(N). We recursively call DFF for each node and mark them as visited once and do not revisit it.
Auxiliary Space Required for DFS Traversal of a Tree
In the case of DFS traversal of a rooted tree using a visited array, the space complexity is O(n).
In the case of DFS traversal of a rooted tree without using a visited array, if we don’t consider the stack for the function calls, then the space complexity is O(1). But if we consider the stack, then the space complexity will be O(h), where h is the tree’s height.
Let n denote the number of nodes in the tree. The best-case height of a binary tree is log(n); hence the best-case space complexity will be O(log(n)).
The height of a skewed binary tree will be O(n). Hence the worst-case space complexity will be O(n) because the depth of the recursion will be the same as the height of the tree. So stack memory consumed is equal to the height of the tree.
Strengths and Weaknesses of DFS Traversal of a Tree
Strength:
DFS is more memory efficient, that is, the auxiliary memory usage of DFS is lesser than BFS (breadth-first search), as a recursive DFS implementation does not require storing anything other than the parent node and the current node.
Weaknesses:
If the tree is very deep, then DFS traversal may waste a lot of time exploring unwanted paths that do not have solutions.
For the problems involving shortest paths, DFS alone cannot guarantee the shortest path.
Given a tree and the root node. Find the maximum path sum from the root node to the leaf node.
Given a tree where each node consists of a character. Check how many palindrome strings can be formed using the characters formed by the path from the root node to the leaf node.
Check out the Learn and Problems pages to continue learning about Tree, Graphs, and other data structure and algorithm concepts.
FAQs on DFS Traversal of a Tree
Question 1: In which cases does DFS traversal of the tree work better than the BFS traversal and vice versa?
Answer: Although DFSand BFS traversals have the same worst-case scenario time complexity, there may be some cases in which it is preferable to use one over the other.
BFS traverses the tree along its breadth, while DFS traverses along its depth. BFS traverses all nodes at a distance d before traversing any node at distance d+1, making it better for the shortest path problem.
When the target nodes are closer to the source node, BFS works better.
When the target nodes are far away from the source node, DFS works better.
When space complexity becomes an issue, it is better to use DFS as the space complexity of DFS is better than BFS.
Question 2: What are the applications of depth-first search?
DFS is used in resolving dependencies, also known as topological sorting. It provides linear ordering of a directed acyclic graph (DAG) in which for every edge u to v, u comes before v.
Preprocessing a tree using DFS allows us to answer the least common ancestor queries efficiently.
DFS is used for detecting cycles in a graph. While performing DFS, if we encounter a back-edge, then a cycle is present in the graph.
DFS is also used to find strongly connected components of a graph.
If you’re looking for guidance and help to nail these questions and more, sign up for our free webinar. As pioneers in the field of technical interview prep, we have trained thousands of software engineers to crack the toughest coding interviews and land jobs at their dream companies, such as Google, Facebook, Apple, Netflix, Amazon, and more!













.png)





