Sorting algorithms are a big part of coding interviews for software engineers. If you’re preparing for an interview at a tech company, brushing up on all sorting algorithms is a must.
In this article, we’ll help you revisit the bucket sort algorithm:
What Is Bucket Sort?
How Does Bucket Sort Work?
Bucket Sort Algorithm
Bucket Sort Pseudocode
Bucket Sort Code
Bucket Sort Complexities
FAQs on Bucket Sort
What Is Bucket Sort?
Bucket sort is a sorting algorithm that divides the elements into several groups called buckets. Once these elements are scattered into buckets, then sorting is done within each bucket. Finally, these sorted elements from each bucket are gathered, in the right order, to get the sorted output.
In short, bucket sort follows what we can call a scatter-sort-gather method.
How Does Bucket Sort Work?
The first order of business is creating the buckets. The number of buckets depends on the kind of data. For example:
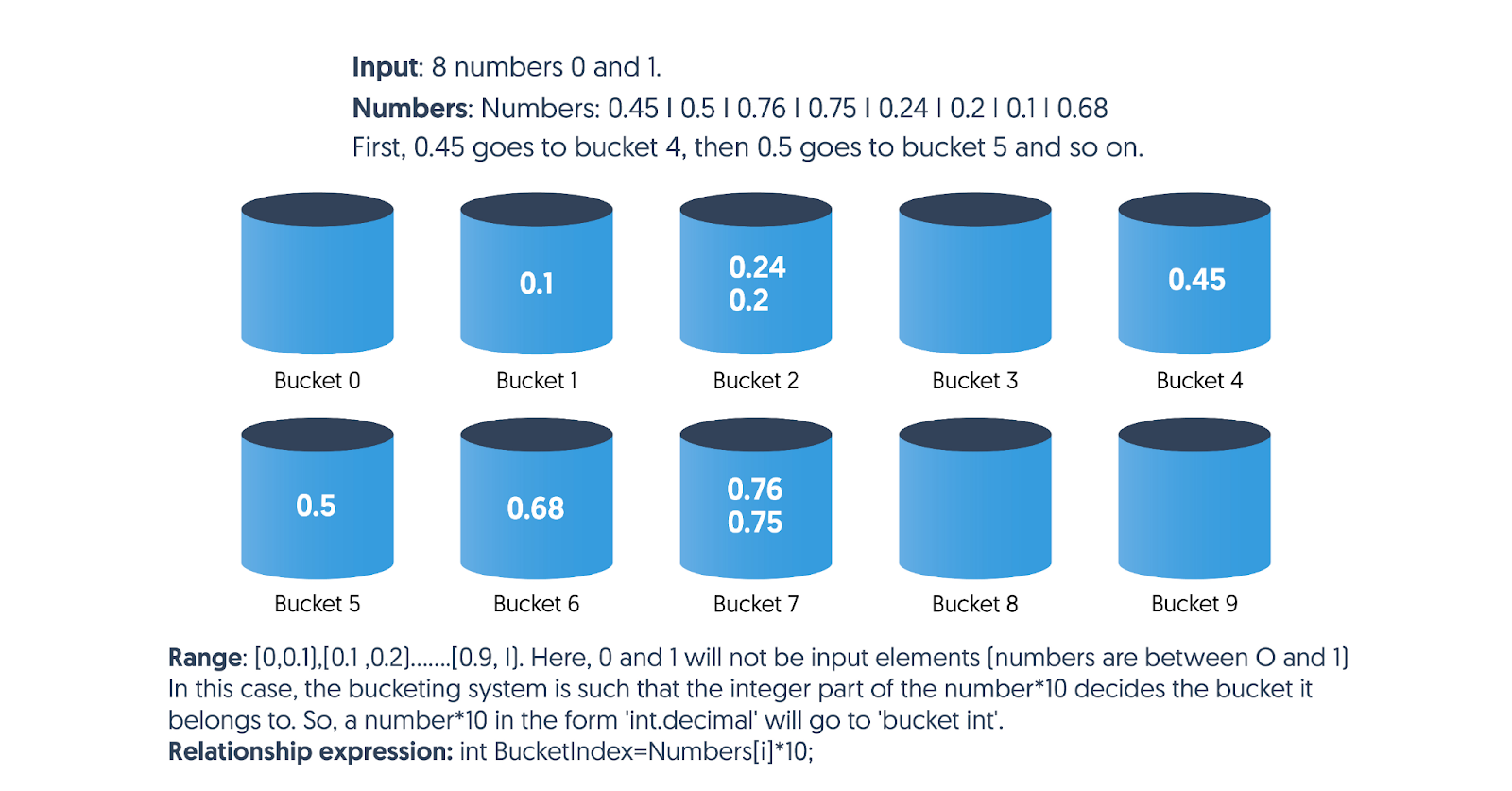
If the elements are real numbers between 0 and 1 (0 and 1 not included):
We can conveniently organize them in 10 buckets.
1st bucket stores all numbers in the range [0, 0.1), 2nd bucket stores the range [0.1,0.2), and so on.
Which buckets the edge cases (0.1, 0.2, and so on) go to can be easily calculated by a clear numerical relationship that we will form between bucket index and elements. For example, say that bucket index is the integer part of number*10. Then for 0.1, its bucket index will be 1.
If the elements are between 0 and 1000:
There can still be 10 buckets.
Buckets can hold values from the ranges [0 to 100), [100 to 200), and so on, with the last bucket being [900 to 1000), maintaining an interval of 100 numbers.
If we want to include 0 and 1000, we can extend the range of the last bucket by 1 to include 1000, and 0 is already included in the initial range distribution.
Numbers in the decimal system don’t need to be scattered in exactly 10 buckets. In the second example, the number of buckets could be 5 — the range size would become 200 instead of 100, and we would keep all numbers between 0 and 199 in the first bucket, 200 to 399 in the second bucket, and so on.
After creating the buckets, we decide on a specific range of elements that could belong in each bucket. The range of any bucket should be a continuous interval, and these intervals should span the input domain. We should also keep in mind that the ranges must not overlap.
Then, based on the range each element belongs to, we put it in its corresponding bucket.
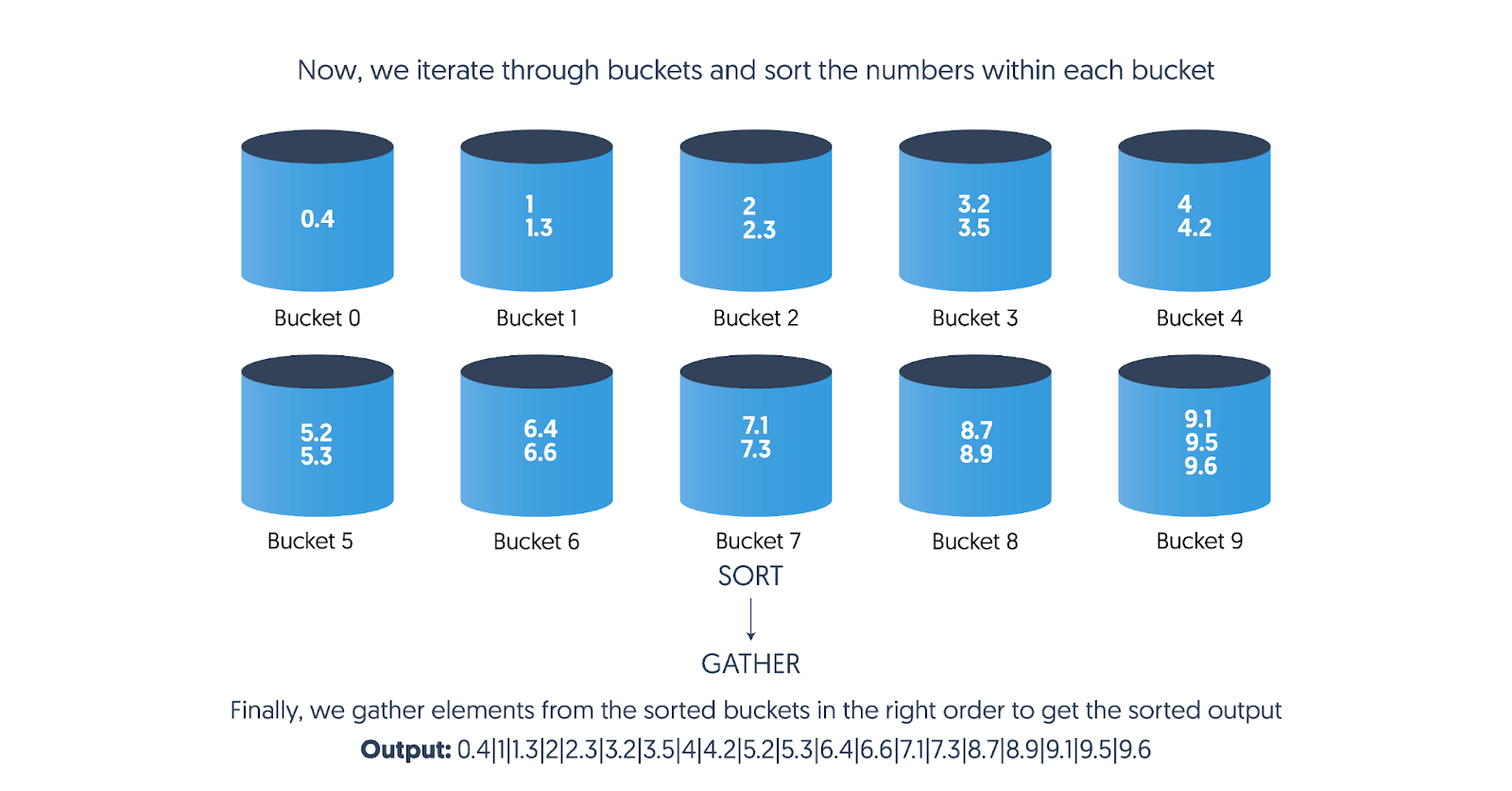
After the elements are in their respective buckets, we sort each bucket’s contents using any fitting sorting algorithm. In some cases, we can also use the same bucket sort algorithm called recursively.
Finally, we take out the sorted elements from the buckets, in order, and join them to get all the elements in their sorted order.
Bucket Sort Algorithm
Create B* buckets, each initialized with zero values.
Assign the range of elements that each bucket can hold.
Scatter: Find the range each element belongs to and put each element into the bucket meant for its range
Sort: Iterate through all buckets and sort elements within each bucket.
Gather the sorted elements from each bucket.
While gathering from the sorted buckets in the right order and joining them, we know that we have sorted the elements fully since bucket-level sorting (i.e., inter-bucket sorting) was already done when we put elements in the bucket!
*Note: The optimal value of the number of (B) and the range of buckets for a given dataset can be decided keeping the following goals in mind:
It should be easy to create a relationship between bucket index and numbers such that a range of numbers falls into each bucket.
If the nature of the distribution of input elements is known, the number of buckets and range should be such that there’s a roughly uniform distribution of elements in each range.
The range of buckets should span the complete range of the input and divide inputs into buckets based on non-overlapping ranges of discrete intervals.
The range of buckets should not overlap.
There’s a tradeoff between space and time complexity. Larger number of buckets means fewer elements per bucket and, therefore, faster sorting. However, to avoid unnecessary space usage, the fewer the buckets, the better the space complexity.
Bucket Sort Pseudocode
bucketSort() Create B empty buckets For each element (i=0 to array size-1) Put each element into the bucket meant for its range. For each bucket (i=0 to B-1) Sort elements within each bucket Concatenate all the sorted elements from each bucket Output the sorted elements end bucketSort()
Here, the iteration is done from 0 to B-1 for the B buckets. We decide the range of elements that can go into each bucket by establishing a relationship between the bucket’s index and elements (so that a range of elements falls into each bucket).
Bucket Sort Code
Here is an example of an array of numbers between 0 and 1 being sorted using bucket sort.
We declare the function bucketSort(float numbers[], int size) and give it two function parameters: the array of numbers to be sorted and the size of the array. We then decide the number of buckets to be created — for numbers in the decimal system, we usually take 10, as there are 10 digits from 0 to 9.
First, we create the 10 buckets.
Then, we decide the range of elements that can go into each bucket.
Once the range of elements that can go into each bucket is decided, we take the array elements one by one and put them in their respective buckets.
Next, we go through each bucket and sort the contents of it.
Finally, the sorted elements from each bucket are collected, in order, and printed out.
#include <iostream>
#include <bits/stdc++.h>
using namespace std;
// Here numbers[] is the array we need to sort and size is the size of
// the array numbers[]
void bucketSort(float numbers[], int size)
{
// Creating 10 buckets, since it's the decimal number system (0-9
// digits).
int base = 10;
vector<float> bucket[base];
// Deciding which numbers go into which buckets and putting them there.
for (int i=0;i<size;i++)
{
// Since numbers are between 0 and 1, we multiply them by 10,
// the base, and take the integer part of the result as the index.
// Range of each bucketIndex is decided. When we multiply decimals
// between 0 and 1 with the base 10, we move the Most Significant
// Digit (MSD) to the left of the decimal. Since the index is of
// type int, it takes only this MSD, which corresponds to the bucket
// index. This is why buckets have numbers sorted according to the
// MSD.
//
// Since numbers are distributed evenly enough over the given range,
// the following relationship between buckets and input numbers is
// ideal for this case of decimals between 0 and 1 to determine
// the range of each bucket:
//
int bucketIndex=base*numbers[i];
// We now know which numbers[i] should go in which bucket index.
//
// Eg- 0.45 will become 0.45*10=4.5, but the bucket index is int,
// so it will take 4. So 4.5 now belongs to the bucket index 4,
// which is the 5th bucket since we start the index from 0.
bucket[bucketIndex].push_back(numbers[i]);
}
// Iterating through individual buckets.
for (int b=0;b<base;b++)
{
// Sorting the contents of individual buckets. sort() sorts the
// elements in ascending order.
sort(bucket[b].begin(),bucket[b].end());
}
// Preparing to store sorted output in order.
int sortedIndex = 0;
for(int i=0;i<base;i++)
{
// Iterating through sorted elements of each bucket and storing
Scatter: The elements are entered in their respective buckets, in the order in which they occur in the original unsorted array input. In this case, the entering starts with bucket 4 for 0.45, which occurs first in the array input.
Sort: At this stage, each bucket is sorted individually.
Gather: Finally, the elements are collected from the sorted buckets, in the right order, to get the final sorted output.
Output: 0.1 0.2 0.24 0.45 0.5 0.68 0.75 0.76
Other Input Types
If the numbers were integers between 0 and 100:
The bucketing system can be such that the integer part of number/10 decides which bucket it belongs to
The expression in that case would be: int BucketIndex= Numbers[i]/10;)
This makes the buckets [0,10), [10,20), and so on, till [90,100)
If the elements were strings instead of numbers:
We could make bucket index 0 to 25 for alphabets from a to z
First characters that match with that bucket index could go in that bucket
Similarly, you can form an optimal relationship between bucket index and numbers for various cases.
Interesting observations: - Counting sort is equivalent to bucket sort with bucket size 1 - Bucket sort with two buckets is equivalent to quicksort with pivot element always set to the middle value - Top-down implementation of radix sort is bucket sort with both the range of values and the number of buckets being a power of 2 or the radix of the numbers that we are going to sort
Bucket Sort Complexity
Time Complexity
The time complexity of bucket sort depends on the internal sorting algorithm used. Here’s why:
When there are too many numbers in the same range, it means that the elements are not uniformly distributed.
In this case, the numbers will likely be placed in the same bucket, or some buckets will have way more elements than others. For example, among buckets B0 to B9, B7 has 90% of the elements.
This means that our internal sorting algorithm will be doing most of the sorting work, making the performance of bucket sort dependent on the internal sorting algorithm used to sort the elements within each bucket.
If prior information on the distribution of elements is absent, the standard library sort may be used.
Worst Case:
In general, bucket sort uses insertion sort for sorting the elements inside each bucket. Insertion sort performs really well when the count of elements that need sorting is small. The buckets are usually set up in a way that each bucket contains a small number of elements, so we can take advantage of this quality.
However, in the worst-case scenario, all elements will end up in a single bucket despite our best efforts. And when that single bucket is sorted using insertion sort, it takes O(n2) time to perform it on all n elements. Therefore, the worst-case runtime of Bucket Sort is O(n2).
Best Case:
The best-case complexity occurs when the elements are uniformly distributed — the number of elements in each bucket is almost equal.
The complexity can be even better if the numbers within each bucket are already sorted, and our sorting algorithm knows how to take advantage of that.
We can use any algorithm that best fits the data. For example, if insertion sort is used in this case, the best case time complexity will be O(n+b) since the best case for insertion sort occurs when the data is already sorted.
Average Case:
Let’s calculate the expected number of numbers in each bucket. It is intuitive that if the ranges of the buckets are of equal size, then in the average case, the expected number of numbers in each bucket would be the same for every bucket. Let that expected number be E.
The sum of the expected number of numbers for all of the buckets should be equal to n. Mathematically, E * n = b must hold. So, E = n / b.
Now, if we apply insertion sort to the numbers, then:
Sorting a single bucket would take O(n2/b2) time
Sorting b buckets would take O(n2/b2 * b) = O(n2/b) time
Choosing a value of “b” in the order of n would result in an expected time complexity of O(n2/n) = O(n)
Space Complexity
The space required for bucket sort depends on the size of the input and the number of buckets created. Therefore, the space complexity of bucket sort is O(nb), where b is the number of buckets.
Bucket Sort FAQs
Question 1: When is bucket sort the most useful?
Bucket sort is mainly useful when the input is uniformly distributed over a range — so no one bucket has most of the elements and most buckets are not empty. It is often used to sort uniformly distributed floating point values. One reason for this is that the range of each bucket can easily be determined.
Another reason is that it's easy to determine a relationship between the bucket index and the number, such that increasing bucket indexes corresponds to increasing range. It is also easy to divide floating point numbers into discrete ranges.
Question 2: When should bucket sort be avoided?
When all or most values fall in just a few buckets, it might be wiser to directly go for a sorting algorithm that works best for that type of data.
Question 3: Is bucket sort a stable sorting algorithm?
Bucket sort is stable if the internal sorting algorithm used to sort it is also stable. Merge sort and insertion sort are examples of stable sorting algorithms that can be used internally. Quicksort is an example of unstable sorting algorithms. (A sorting algorithm is said to be stable if for any two elements with the same key, the relative order of the two elements is preserved in the sorted output as it is in the original input.)
Question 4: Is bucket sort an in-place sorting algorithm?
Since the inputs are sorted by placing them into several buckets, the sorting is not happening in-place. Bucket sort is not an in-place sorting algorithm.
Question 5: Can the ranges of individual buckets be of different intervals/sizes?
Yes. The intervals for each bucket do not always need to be of the same size. However, if a uniform enough distribution of elements is assumed and the range of input is known, equal intervals will help ensure elements are distributed more uniformly within buckets.
Are You Ready to Nail Your Next Coding Interview?
Sorting algorithms interview questions feature in almost every coding interview for software developers. If you’re looking for guidance and help to nail these questions and more, sign up for our free webinar.
As pioneers in the field of technical interview prep, we have trained thousands of software engineers to crack the toughest coding interviews and land jobs at their dream companies, such as Google, Facebook, Apple, Netflix, Amazon, and more!









.png)





