Learning basic graph traversal algorithms is important for any software developer to crack coding rounds of interviews at top tech companies.
Breadth-first search is one such graph algorithm, which helps solve easy as well as advanced graph problems. Knowing this algorithm can boost your chances of clearing tech interview questions on data structure and algorithms.
In this article, we cover everything you need to know about the BFS algorithm, including:
What Is Graph Traversal?
What Is BFS?
Applications of BFS
How Does BFS Work?
BFS Algorithm
BFS Pseudocode
BFS Code
BFS for Disconnected Graph
BFS vs. DFS
BFS FAQs
What Is Graph Traversal?
Graph traversal is the process of visiting every vertex and edge of a graph at least once. The order in which the vertices are visited is important. There may be many such orders, but the challenge is to find the traversal technique best suited to solve a particular problem.
What Is BFS?
Breadth-first search (BFS) is a graph search and traverse algorithm used to solve many programming and real-life problems. It follows a simple, level-based approach. We can easily solve many problems in computer science by modeling them in terms of graphs. For example: analyzing networks, mapping routes, scheduling, and more.
BFS Applications
Finding the shortest path: In an unweighted graph, the shortest path between two nodes is the path with the least number of edges. BFS can be used to find the shortest path between a source node and all the remaining nodes in an unweighted graph.
Finding the minimum spanning tree: After some modifications, this algorithm can be used to find the minimum spanning tree for unweighted graphs.
Detecting a cycle: This algorithm can be used to detect a cycle in graphs.
Finding a path: We can use BFS to check whether a path exists between two nodes.
Peer-to-peer networks: In P2P networks, like BitTorrent, BFS is used to find all neighbor nodes.
Broadcasting networks: In network broadcasting, broadcasted packets are guided by the BFS algorithm to reach all target nodes.
GPS navigation systems: BFS is used to find all neighboring locations.
Search engine crawlers: The main idea behind crawlers is to start from the source page, follow all links from that source to other pages, and keep repeating the same until the objective for crawling is completed.
Social networking websites: We can find the number of people within a given distance “k” from a person in a social network using BFS.
Connected component: We can use BFS to find all the nodes within a connected component of a graph.
Bipartite: This algorithm can be used to check if a graph is bipartite.
How Does BFS Work?
The BFS algorithm traverses the graph across its breadth. It's a layerwise traversal algorithm. BFS starts traversing the graph from a chosen “root” node, say Source, and explores all of its neighbor nodes at its next depth before moving on to the other nodes.
Let’s look at the algorithm to understand this better.
BFS Algorithm
Step 1: Create an empty queue to store the nodes to be visited and a boolean vector to track the visited nodes. Initially, no node is visited.
Step 2: Choose a starting node, mark it visited, and add it to the queue.
Step 3: Extract the front item of the queue, add it to the BFS order, and traverse through the list of that node's adjacent nodes.
Step 4: If a node in that list has not been already visited, mark it visited, and add it to the back of the queue.
Step 5: Keep repeating steps 3 and 4 until the queue is empty.
Let’s take an example. We’ll use an undirected graph with six vertices.
We first choose a node to start BFS and put it in the queue after marking it “visited.” In this case, we have chosen 0.
We will repeatedly pop the front element of the queue, traverse its neighboring nodes, and add it to “BFS Order.” Currently, we have 0 at the front of the queue, and none of its neighbors are visited. So, we’ll mark them as visited and add all of them to the queue.
Now, we have node 1 at the front of the queue. It has only two neighbors, 0 and 3, which have been marked visited in a previous step. So, we'll move on to the next step.
Here, we have 3 at the front of the queue. It has only one unvisited neighbor, 4. So, we will mark it visited and add it to the queue.
For node 2, we add its unvisited neighbor 5 to the queue.
For node 4, all its neighbors are already visited — we move on to the next step.
After extracting 5 from the queue, all the graph elements have been visited, and there are no elements left in the queue. BFS on this graph is complete.
If you look closely, you will notice that we have visited the nodes layerwise, that is, in the order of their level. Let’s understand what that means.
A level structure of an undirected graph is a partition of the vertices into subsets that are at the same distance from a given root vertex. Here:
On level 0, we have only node 0, the root vertex
On level 1, we have 1, 3, and 2
On the last level, we have 4 and 5
Now, if you observe the obtained BFS Order, we have visited the nodes in the order of their levels.
BFS Pseudocode
Getting the hang of it? Here’s the pseudocode for BFS. Go ahead and implement it in a programming language of your choice.
BFS (graph G, int start_node)
create a queue Q
mark start_node as visited.
Q.enqueue(start_node)
while (Q is not empty)
curr_node = Q.dequeue( )
for all neighbours adj_node of curr_node in Graph G
if adj_node is not visited
Q.enqueue(adj_node)
mark adj_node as visited
BFS Code
We’ve chosen C++ to demonstrate how the code works. You can implement the same in C, Java, Python, or any other programming language.
// C++ implementation of BFS
#include
using namespace std;
// Function to add the edge in an undirected graph
void addEdge(vector g[], int u, int v) {
g[u].push_back(v);
g[v].push_back(u);
}
// BFS Function for node 'root'
void BFS(vector g[], vector &visited, int root) {
// Declare a queue to store all the unvisited nodes of root
queue q;
// Mark root as visited
visited[root] = true;
q.push(root);
while(!q.empty()) {
// Get the front element of the queue
int u = q.front();
q.pop();
cout << u << " ";
// Get all neighboring nodes of the current element u.
for (auto v : g[u]) {
/* If the neighboring node v has not been visited,
then mark it visited and add it to the queue. */
if (!visited[v]) {
visited[v] = true;
q.push(v);
}
}
}
}
int main() {
// Number of nodes/vertices
int V = 6;
// vector array to store the edges of the graph
vector g[V];
/* boolean vector to store the visited status
of the nodes. Initially all marked false. */
vector visited(V, false);
// Adding a few edges to the graph
addEdge(g, 0, 1);
addEdge(g, 0, 3);
addEdge(g, 1, 3);
addEdge(g, 2, 0);
addEdge(g, 3, 4);
addEdge(g, 2, 5);
addEdge(g, 4, 5);
cout << "The BFS Traversal is : \n";
// Calling the BFS function with root node 0
BFS(g, visited, 0);
return 0;
}
Code Output
The BFS Traversal is: 0 1 3 2 4 5
BFS Complexity
Time Complexity
In this algorithm, we traverse each edge and each node at least once. Therefore, the time complexity can be expressed as O(V + E) — here, V is the number of nodes and E is the number of edges.
It is important to note that the number of edges in a graph can vary from 0 to n * (n -1) / 2 in an undirected graph. And so:
Best-case time complexity: O(V), when the graph is very sparse
Worst-case time complexity: O(V2), when the graph is very dense.
Another implementation of BFS uses an adjacency matrix instead of an adjacency list (which we have used here) for storing the graph. In that case, the time complexity will always be O(V2).
If the graph is a tree, then the complexity becomes O(V), as the number of edges in a tree equals one less than the number of vertices.
Space Complexity
The space complexity of the algorithm is O(V). In both implementations of BFS (using adjacency list and adjacency matrix), the extra space required is in the order of V (for the queue and the boolean vector visited).
The space required for the graph representation is O(V + E) for an adjacency list and O(V2) for an adjacency matrix representation.
BFS for Disconnected Graph
In the above implementation, we assumed that the graph is connected — all the nodes are reachable from any node. But, we may have to work on disconnected graphs too in some scenarios.
With a little modification to the above implementation, we can apply BFS on disconnected graphs too.
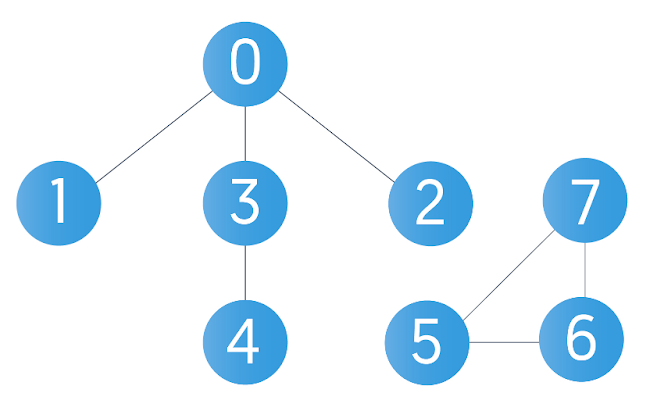
Following is an example of a disconnected graph (with 8 nodes) and the program to traverse the graph using BFS.
BFS Code for Disconnected Graph
// C++ implementation of BFS
#include
using namespace std;
// Function to add the edge in an undirected graph
void addEdge(vector g[], int u, int v) {
g[u].push_back(v);
g[v].push_back(u);
}
// BFS Function for node 'root'
void BFS(vector g[], vector &visited, int root) {
// Declare a queue to store all the unvisited nodes of root
queue q;
// Mark root as visited
visited[root] = true;
// Add root to the queue
q.push(root);
while(!q.empty()) {
// Getting the queue’s front element
int u = q.front();
q.pop();
cout << u << " ";
// Get all neighboring nodes of the current element u.
for (auto v : g[u]) {
/* If the neighboring node v has not been visited,
then mark it visited and add it to the queue. */
if (!visited[v]) {
visited[v] = true;
q.push(v);
}
}
}
// Adding a line to separate different components of the graph
cout << '\n';
}
int main() {
// Number of nodes/vertices
int V = 8;
// vector array to store the edges of the graph
vector g[V];
/* boolean vector to store the visited status
of the nodes initially all marked false */
vector visited(V, false);
// Adding a few edges to the graph
addEdge(g, 0, 1);
addEdge(g, 0, 3);
addEdge(g, 2, 0);
addEdge(g, 3, 4);
addEdge(g, 5, 6);
addEdge(g, 6, 7);
addEdge(g, 7, 5);
cout << "The BFS Traversal is : \n";
/* Calling the BFS function on vertices that
has not been visited yet */
for (int i = 0; i < V; i++)
if (!visited[i])
BFS(g, visited, i);
return 0;
}
Question 1: How can BFS be used to detect a cycle in an undirected graph?
Answer: We can detect if an undirected graph has a cycle by performing a BFS traversal of the given graph. For every visited vertex “v,” if there is an adjacent “u” such that u is already visited and u is not a parent of v, then there is a cycle in the graph.
If we don’t find such an adjacent node for any vertex, we can conclude that there is no cycle in the graph. Note that we have assumed that there are no parallel edges between any two vertices in the graph; otherwise, we can say that the graph contains a cycle without even applying BFS.
Question 2: Why does BFS use the “queue” data structure over other data structures like “stack”?
Answer: The First In First Out (FIFO) concept of a queue ensures that things that are discovered first are explored first, before exploring those that are discovered subsequently — this is the key for this algorithm. Therefore, a queue is the most optimum data structure for implementing BFS.
Stacks are exactly the opposite of queues. Stacks apply the Last In First Out (LIFO) concept, which is optimum for the depth-first search algorithm.
Question 3: Can we find the shortest path between two nodes using BFS?
Answer: We can find the shortest paths between nodes using BFS but only for an unweighted graph. For a given node “u” of a connected graph “G,” we can find the shortest path between u and all other nodes of the graph G by applying BFS on the graph with the root node as u.
We can do this by storing the immediate parent of each node in an array while visiting the vertices in the BFS function and then creating the path for each node using the parent array. The parent of a node is its neighbor that was visited the earliest.
Let’s suppose we have the parent array “p” of size “V,” for a graph G with V vertices, and node 0 is the root. Suppose we want to find the path between the root node and all the other nodes of the graph:
For all i, where 0 < i < V holds, Let pi be the parent of node i. p[0] can be set as -1.
The following pseudocode will do the job:
for i : 1 to V - 1
j = i
while p[j] != -1
print(j)
j = p[j]
Note that the above pseudocode will print the path in reversed order.
Question 4: Is BFS a complete and optimal algorithm?
Answer: If an algorithm is complete, it means that if at least one solution exists, then the algorithm is guaranteed to find a solution in a finite amount of time.
If a search algorithm is optimal, it means when it finds a solution, it finds the best solution.
BFS is both complete and optimal.
Are You Ready to Nail Your Next Coding Interview?
Basic graph traversal algorithms can help you solve many questions during your tech interview as a software developer. If you’re looking for guidance and support to nail these questions and more, sign up for our free webinar.
As pioneers in the field of technical interview prep, we have trained thousands of software engineers to crack the toughest coding interviews and land jobs at their dream companies, such as Google, Facebook, Apple, Netflix, Amazon, and more!

















.png)





