Can we trust every piece of data at our disposal to be accurate? Every business, no matter regardless of size, needs data. However, without reliable data, organizations would not be able to decide what is best for their consumers and internal operations. The first and most important stage in any machine learning method is data preprocessing. Businesses may obtain clean, correct data to train their algorithms on and work toward better services with the use of data preprocessing techniques in machine learning.
What is Data Preprocessing?
Data preprocessing is an operation that entails converting unprocessed data to address concerns related to its insignificance, regularity, or the absence of a proper statistical description to produce a dataset that can be analyzed in an accessible format. Data preprocessing techniques have been developed to help train artificial intelligence and machine learning models and make predictions using them.
Data preprocessing changes the data into a form that can be analyzed in data mining, machine learning, and other data science operations with greater effectiveness and speed. The techniques are typically applied at the beginning of the machine learning and AI development lifecycle to ensure reliable findings.
Text, photos, video, and other types of unprocessed, real-world data are unstructured. In addition to having the potential to be inaccurate and inconsistent, it can often be lacking in essential information and lacks a consistent, regular layout.
Machines prefer to work with neat and orderly data; they process data as 1s and 0s. Therefore, it is simple to calculate structured data such as whole numbers and percentages. However, raw information needs to be filtered and prepared in the form of text and graphics before processing.
Need for Machine Learning Data Preprocessing Techniques
Algorithms that gain insight from data are basically statistical computations that depend on information from a database. Therefore, as the expression states, “if waste enters, waste comes out.” Only high-quality data fed into the computers can make the data projects effective.
If you happen to overlook the data preprocessing stage, it will have an impact on your results subsequent to when you decide to use this dataset in a machine learning framework. The majority of models are unable to manage missing values.
Here are some of the reasons why different data preprocessing techniques are needed for the machine learning model:
Preprocessing the data will increase the dataset’s quality and precision because outliers, high dimensionality, and inaccurate information influence certain portions. This step is essential to perform any required changes to the data before implementing it to use the machine learning models.
Data preprocessing methods incorporate Principal Analysis (PCA) to decrease the total number of input data characteristics, improving the model's accuracy and making the dataset easier to handle and operationally economical.
Preprocessing data aids in standardizing or adjusting features, and this is particularly significant for models that are responsive to data entered scale. It also ensures that every characteristic is scaled similarly, which is essential for several machine learning algorithms to operate accurately.
Since some datasets commonly have missing data, which may significantly hamper the effectiveness of machine learning models, data preprocessing techniques like imputation are essential for successfully handling missing data.
What Makes Quality Data?
Data is the most important component of machine learning models. Good quality data would provide the best quality results for any organization. Certain factors make quality data using the data preprocessing techniques in machine learning, such as the following:
The data should have a good degree of accuracy. The accuracy of a dataset can be impacted by redundant data, outdated details and oversights.
There should be no inconsistencies in the data. You can receive various responses to a single query if the data is unreliable.
The raw data set should not contain any blank fields or have any missing fields. This feature gives data scientists accessibility to a detailed and perfect view of the circumstances that the data reflects, enabling them to conduct precise analyses.
A dataset is regarded as acceptable if the data samples are in the right way, are within the assigned limits, and are steadily belonging to the relevant kind. It is challenging to set up and assess unreliable datasets.
Data must be obtained soon after the situation for which it was gathered happens. Every dataset degrades with time because it no longer accurately reflects the current condition of the global community.
What are Data Preprocessing Techniques?
For the major data preprocessing techniques, machine learning, Python is the most widely used language. The data preprocessing techniques include:
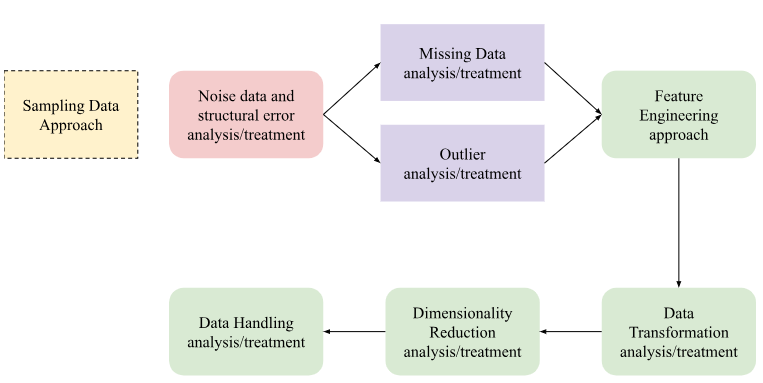
Data Cleaning
Finding and correcting flawed and erroneous information from your dataset is one of the most essential elements of the data preprocessing procedure for enhancing its overall quality. Data cleaning will resolve all inconsistencies discovered during the data quality review. Data inaccuracies might develop due to human mistakes (the data was recorded in the incorrect field). Deduplication is the process that could be used to eliminate duplicate values to prevent bias in that data item. Based on the type of data you have to work with, you might have to run the data across several kinds of cleaners.
Dimensionality Reduction
A practical dataset usually consists of a large number of variables; if we do not reduce this quantity, it can have an impact on how well the model performs when we eventually input this dataset. Decreasing the number of features while retaining as much diversity in the dataset as achievable is likely to have a favorable influence on many kinds of aspects.
You can implement different dimensionality reduction methods to improve our data for future use.
Feature Selection: Feature selection is the process of choosing the variables (features) that are most essential for the prediction variables; in a nutshell, choosing the features most vital to your model's functioning.
Linear methods: Linear transformations are used in linear methods to lower the dimensionality of the data. The PCA method is used to modify the original features while keeping the attributes of it.
Non-linear methods: When the data cannot be interpreted in a linear space, non-linear methods (also sometimes referred to as manifold learning methods) are applied.
Multidimensional scaling: The data are transformed using the Multi-Dimensional Scaling (MDS) method to a smaller dimension, and any pairs that were near in the higher dimension are kept in the lower dimension likewise.
Feature Engineering
The feature engineering strategy is utilized to develop enhanced features for the data set that will boost the efficiency of the model. Those features are manually generated from the present features by performing a few modifications on them. We mostly depend on domain-specific knowledge for generating these features. The process of feature engineering is commonly used where the initial features are complicated and high-dimensional. Techniques like PCA, linear discriminant analysis (LDA), and non-negative matrix factorization (NMF) can be used to accomplish this.
Data Transformation
Data transformation is the process of converting data between different formats. Certain algorithms require that the input data be modified; hence, forgetting to do this could result in inadequate model accuracy or even biases. Standardization, normalization and discretization are standard data transformation processes. While standardization modifies data to have a zero mean and unit variance, normalization ranges data to a uniform spectrum. Discretization is the process through which ongoing data is converted into distinct groups.
Data Handling
When working with practical data grouping, one of the main prevalent challenges is that the categories are unbalanced, which strongly biases the model. The major techniques used in data handling are:
Oversampling: The oversampling method involves adding artificial data from the minority category to your dataset to make it larger. SMOTE (Synthetic Minority Oversampling Technique) is the most widely used method for this.
Undersampling: The undersampling strategy is the practice of cutting your dataset and deleting actual data from the majority class. TomekLinks, which eliminates observations based on the nearest neighbor, and Edited Nearest Neighbors (ENN), which employs k-nearest neighbors rather than just one, as in Tomek, are the key ones utilized in this methodology.
Hybrid: The hybrid strategy incorporates the approaches of oversampling and undersampling in your dataset.
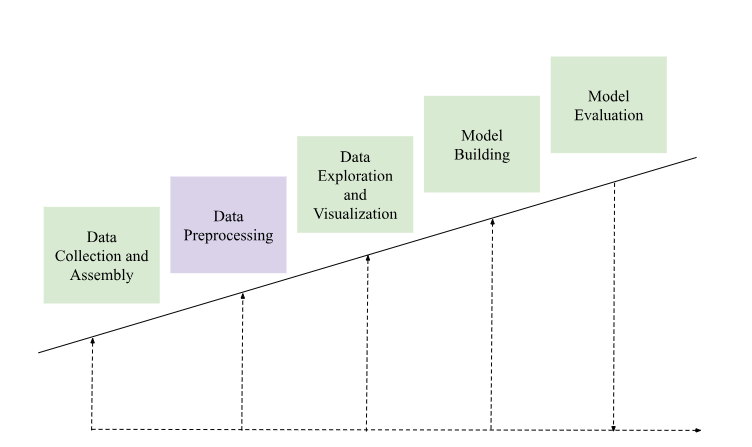
General Outline of Machine Learning Model Using Data Preprocessing Techniques
Gear Up With Data Preprocessing Techniques in Machine Learning
It will not be an overstatement if we say, “Data is everything.” Every organization or business needs data to improve their products and services. Data cleaning is always an important step in every operation. Machine learning models are important for major operations. Data preprocessing techniques in machine learning help prepare ideal data for the functioning of the models. Interview Kickstart has always been at the forefront of helping enthusiast data scientists to learn and explore machine learning in-depth and get into their desired company. Join our machine learning program to excel in data preprocessing and other machine learning techniques.
FAQs about Data Preprocessing Techniques in Machine Learning
Q1. What are the major steps in data preprocessing?
The major steps in data preprocessing are data cleaning, data integration, data reduction and data transformation.
Q2. How many types of data preprocessing are there?
There are two types of data preprocessing: data cleaning and feature engineering.
Q3. What is EDA in machine learning?
Data scientists use exploratory data analysis (EDA), which often includes the use of data visualization techniques, to explore and analyze data sets and highlight their key properties.
Q4. What is NLP preprocessing?
The basic NLP preprocessing includes sentence segmentation, lowercasing, word tokenization, stemming or lemmatization, stop word removal, and spelling correction.
Q5. What is preprocessing vs. post-processing machine learning?
Pre-processing scripts in machine learning are executed in advance of the value and validity rules verification, while post-processing scripts are executed following these operations.
Last updated on:
April 1, 2024
Author
Vartika Rai
Product Manager at Interview Kickstart | Ex-Microsoft | IIIT Hyderabad | ML/Data Science Enthusiast. Working with industry experts to help working professionals successfully prepare and ace interviews at FAANG+ and top tech companies
Attend our Free Webinar on How to Nail Your Next Technical Interview
Taking you to the Calendly...
Oops! Something went wrong while submitting the form.
Register for our webinar
How to Nail your next Technical Interview
Step 1
Step 2
Congratulations!
You have registered for our webinar
Oops! Something went wrong while submitting the form.
Step 1
Step 2
Confirmed
You are scheduled with Interview Kickstart.
Redirecting...
Oops! Something went wrong while submitting the form.
Data Preprocessing Techniques: The Foundation of Clean ML Data
Worried About Failing Tech Interviews?
Attend our webinar on "How to nail your next tech interview" and learn
Hosted By
Ryan Valles
Founder, Interview Kickstart
Our tried & tested strategy for cracking interviews









.png)





